LiteLLM Proxy - 在 Locust 上进行 1K RPS 负载测试
关于如何在 locust 上使用 LiteLLM Proxy 达到 1K+ RPS 的教程
测试前检查清单
- 确保您使用的是 最新的
-stable版本 的 litellm - 确保您遵循 所有 生产环境最佳实践
- Locust - 确保您的 Locust 实例每秒能创建 1K+ 请求
- 👉 您可以使用我们此处维护的 locust 实例
- 如果您自行托管 locust
- 使用此 LiteLLM Proxy 运行的机器配置
- 企业版 LiteLLM - 在您的
proxy_config.yaml中使用prometheus作为回调来获取负载测试的指标。将litellm_settings.callbacks设置为监控成功/失败/所有类型的错误。litellm_settings:
callbacks: ["prometheus"] # Enterprise LiteLLM Only - use prometheus to get metrics on your load test
使用此配置进行测试
注意: 我们正在迁移到吞吐量提高 10 倍的 aiohttp。建议使用 aiohttp_openai/ 提供商进行负载测试。
model_list:
- model_name: "fake-openai-endpoint"
litellm_params:
model: aiohttp_openai/any
api_base: https://your-fake-openai-endpoint.com/chat/completions
api_key: "test"
负载测试 - 模拟 OpenAI 端点
预期性能
| 指标 | 值 |
|---|---|
| 每秒请求数 | 1174+ |
| 中位数响应时间 | 96ms |
| 平均响应时间 | 142.18ms |
运行测试
- 将
fake-openai-endpoint添加到您的 proxy config.yaml 并启动您的 litellm proxy。litellm 提供了一个托管的fake-openai-endpoint,您可以对其进行负载测试。
model_list:
- model_name: fake-openai-endpoint
litellm_params:
model: aiohttp_openai/fake
api_key: fake-key
api_base: https://exampleopenaiendpoint-production.up.railway.app/
litellm_settings:
callbacks: ["prometheus"] # Enterprise LiteLLM Only - use prometheus to get metrics on your load test
pip install locust在您的本地机器上创建一个名为
locustfile.py的文件。从 此处 复制 litellm 负载测试的内容。启动 locust。在与您的
locustfile.py(步骤 2) 相同的目录中运行locust。locust -f locustfile.py --processes 4在 locust 上运行负载测试
访问 http://0.0.0.0:8089 上的 locust UI
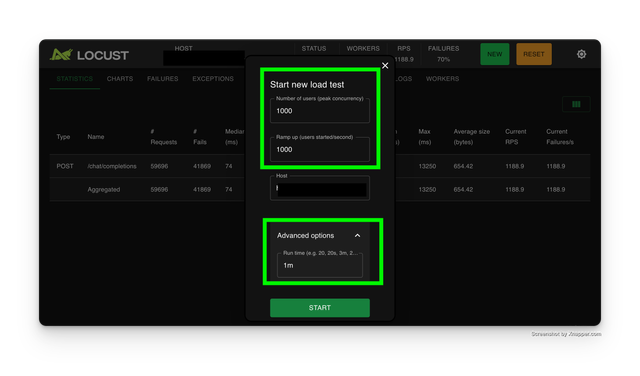
设置 用户数=1000,爬升用户数=1000,主机=您的 LiteLLM Proxy 的基础 URL。
预期结果
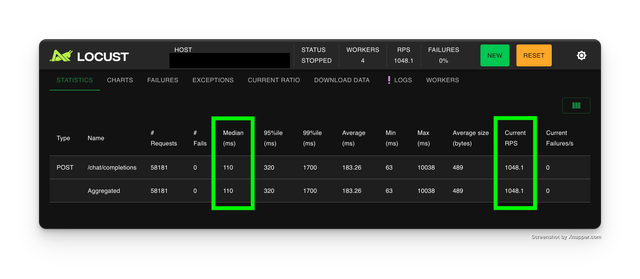
负载测试 - 带有速率限制的端点
对 2 个 LLM 部署运行负载测试,每个部署配有 10K RPM 配额。预计将看到约 20K RPM。
预期性能
- 我们期望在 1 分钟内看到 20,000+ 次成功响应
- 剩余请求失败是因为端点超过了其 10K RPM 配额限制 - 来自 LLM API 提供商
| 指标 | 值 |
|---|---|
| 1 分钟内的成功响应数 | 20,000+ |
| 每秒请求数 | ~1170+ |
| 中位数响应时间 | 70ms |
| 平均响应时间 | 640.18ms |
运行测试
- 在您的 config.yaml 中添加 2 个
gemini-vision部署。每个部署可处理 10K RPM。(我们在下面的/v1/projects/bad-adroit-crow路由上设置了一个具有 1000 RPM 速率限制的模拟端点)
信息
所有使用 model="gemini-vision" 的请求将在 2 个部署之间进行平均负载均衡。
model_list:
- model_name: gemini-vision
litellm_params:
model: vertex_ai/gemini-1.0-pro-vision-001
api_base: https://exampleopenaiendpoint-production.up.railway.app/v1/projects/bad-adroit-crow-413218/locations/us-central1/publishers/google/models/gemini-1.0-pro-vision-001
vertex_project: "adroit-crow-413218"
vertex_location: "us-central1"
vertex_credentials: /etc/secrets/adroit_crow.json
- model_name: gemini-vision
litellm_params:
model: vertex_ai/gemini-1.0-pro-vision-001
api_base: https://exampleopenaiendpoint-production-c715.up.railway.app/v1/projects/bad-adroit-crow-413218/locations/us-central1/publishers/google/models/gemini-1.0-pro-vision-001
vertex_project: "adroit-crow-413218"
vertex_location: "us-central1"
vertex_credentials: /etc/secrets/adroit_crow.json
litellm_settings:
callbacks: ["prometheus"] # Enterprise LiteLLM Only - use prometheus to get metrics on your load test
pip install locust在您的本地机器上创建一个名为
locustfile.py的文件。从 此处 复制 litellm 负载测试的内容。启动 locust。在与您的
locustfile.py(步骤 2) 相同的目录中运行locust。locust -f locustfile.py --processes 4 -t 60在 locust 上运行负载测试
访问 http://0.0.0.0:8089 上的 locust UI 并使用以下设置
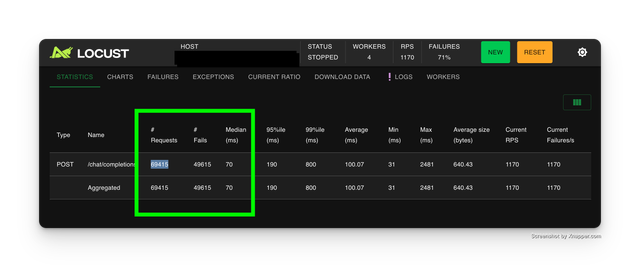
预期结果
- 1 分钟内的成功响应数 = 19,800 = (69415 - 49615)
- 每秒请求数 = 1170
- 中位数响应时间 = 70ms
- 平均响应时间 = 640ms
用于调试负载测试的 Prometheus 指标
使用以下 Prometheus 指标来调试您的负载测试/失败
| 指标名称 | 描述 |
|---|---|
litellm_deployment_failure_responses | 特定 LLM 部署的失败 LLM API 调用总数。标签:"requested_model", "litellm_model_name", "model_id", "api_base", "api_provider", "hashed_api_key", "api_key_alias", "team", "team_alias", "exception_status", "exception_class" |
litellm_deployment_cooled_down | 部署被 LiteLLM 负载均衡逻辑冷却的次数。标签:"litellm_model_name", "model_id", "api_base", "api_provider", "exception_status" |
用于运行 Locust 的机器配置
| 指标 | 值 |
|---|---|
locust --processes 4 | 4 |
负载测试机器上的 vCPU | 2.0 vCPUs |
负载测试机器上的 内存 | 450 MB |
负载测试机器的 副本数 | 1 |
用于运行 LiteLLM Proxy 的机器配置
👉 要获得 1K+ RPS,LiteLLM Proxy 的副本数=4
| 服务 | 配置 | CPU | 内存 | 架构 | 版本 |
|---|---|---|---|---|---|
| 服务器 | t2.large. | 2vCPUs | 8GB | x86 |
测试使用的 Locust 文件
import os
import uuid
from locust import HttpUser, task, between
class MyUser(HttpUser):
wait_time = between(0.5, 1) # Random wait time between requests
@task(100)
def litellm_completion(self):
# no cache hits with this
payload = {
"model": "fake-openai-endpoint",
"messages": [{"role": "user", "content": f"{uuid.uuid4()} This is a test there will be no cache hits and we'll fill up the context" * 150 }],
"user": "my-new-end-user-1"
}
response = self.client.post("chat/completions", json=payload)
if response.status_code != 200:
# log the errors in error.txt
with open("error.txt", "a") as error_log:
error_log.write(response.text + "\n")
def on_start(self):
self.api_key = os.getenv('API_KEY', 'sk-1234')
self.client.headers.update({'Authorization': f'Bearer {self.api_key}'})