📈 Prometheus 指标
LiteLLM 暴露了一个 /metrics 端点供 Prometheus 拉取(Poll)
快速开始
如果你正在使用 LiteLLM CLI 并通过 litellm --config proxy_config.yaml 启动,你需要执行 pip install prometheus_client==0.20.0。此包已预装在 litellm Docker 镜像中
将以下内容添加到你的代理配置文件 config.yaml 中
model_list:
- model_name: gpt-3.5-turbo
litellm_params:
model: gpt-3.5-turbo
litellm_settings:
callbacks: ["prometheus"]
启动代理
litellm --config config.yaml --debug
测试请求
curl --location 'http://0.0.0.0:4000/chat/completions' \
--header 'Content-Type: application/json' \
--data '{
"model": "gpt-3.5-turbo",
"messages": [
{
"role": "user",
"content": "what llm are you"
}
]
}'
在 /metrics 查看指标,访问 https://:4000/metrics
https://:4000/metrics
# <proxy_base_url>/metrics
虚拟密钥、团队、内部用户
用于按 用户、密钥、团队等 进行跟踪
| 指标名称 | 描述 |
|---|---|
litellm_spend_metric | 总支出,按 "user", "key", "model", "team", "end-user" 分类 |
litellm_total_tokens | 输入 + 输出 token 数,按 "end_user", "hashed_api_key", "api_key_alias", "requested_model", "team", "team_alias", "user", "model" 分类 |
litellm_input_tokens | 输入 token 数,按 "end_user", "hashed_api_key", "api_key_alias", "requested_model", "team", "team_alias", "user", "model" 分类 |
litellm_output_tokens | 输出 token 数,按 "end_user", "hashed_api_key", "api_key_alias", "requested_model", "team", "team_alias", "user", "model" 分类 |
团队 - 预算
| 指标名称 | 描述 |
|---|---|
litellm_team_max_budget_metric | 团队最大预算 标签: "team_id", "team_alias" |
litellm_remaining_team_budget_metric | 团队剩余预算 (在 LiteLLM 上创建的团队) 标签: "team_id", "team_alias" |
litellm_team_budget_remaining_hours_metric | 团队预算重置前的剩余小时数 标签: "team_id", "team_alias" |
虚拟密钥 - 预算
| 指标名称 | 描述 |
|---|---|
litellm_api_key_max_budget_metric | API 密钥最大预算 标签: "hashed_api_key", "api_key_alias" |
litellm_remaining_api_key_budget_metric | API 密钥剩余预算 (在 LiteLLM 上创建的密钥) 标签: "hashed_api_key", "api_key_alias" |
litellm_api_key_budget_remaining_hours_metric | API 密钥预算重置前的剩余小时数 标签: "hashed_api_key", "api_key_alias" |
虚拟密钥 - 速率限制
| 指标名称 | 描述 |
|---|---|
litellm_remaining_api_key_requests_for_model | LiteLLM 虚拟 API 密钥的剩余请求数,仅当该虚拟密钥设置了模型特定的速率限制 (rpm) 时。标签: "hashed_api_key", "api_key_alias", "model" |
litellm_remaining_api_key_tokens_for_model | LiteLLM 虚拟 API 密钥的剩余 token 数,仅当该虚拟密钥设置了模型特定的 token 限制 (tpm) 时。标签: "hashed_api_key", "api_key_alias", "model" |
启动时初始化预算指标
如果你想让 litellm 发出所有密钥、团队的预算指标,无论它们是否接收到请求,请在 config.yaml 中将 prometheus_initialize_budget_metrics 设置为 true
工作原理
- 如果
prometheus_initialize_budget_metrics设置为true- 每 5 分钟 litellm 运行一个 cron 作业从数据库读取所有密钥、团队
- 然后它会为每个密钥、团队发出预算指标
- 这用于填充
/metrics端点上的预算指标
litellm_settings:
callbacks: ["prometheus"]
prometheus_initialize_budget_metrics: true
代理级别跟踪指标
用于跟踪 LiteLLM 代理的整体使用情况。
- 跟踪流向代理的实际流量速率
- 对代理发起的客户端请求及其失败次数
| 指标名称 | 描述 |
|---|---|
litellm_proxy_failed_requests_metric | 来自代理的失败响应总数 - 客户端未从 litellm 代理获得成功响应。标签: "end_user", "hashed_api_key", "api_key_alias", "requested_model", "team", "team_alias", "user", "exception_status", "exception_class" |
litellm_proxy_total_requests_metric | 发送到代理服务器的请求总数 - 跟踪客户端请求数量。标签: "end_user", "hashed_api_key", "api_key_alias", "requested_model", "team", "team_alias", "user", "status_code" |
LLM 提供商指标
用于 LLM API 错误监控以及跟踪剩余速率限制和 token 限制
跟踪的标签
| 标签 | 描述 |
|---|---|
| litellm_model_name | LiteLLM 使用的 LLM 模型名称 |
| requested_model | 请求中发送的模型 |
| model_id | 部署的 model_id。由 LiteLLM 自动生成,每个部署都有一个唯一的 model_id |
| api_base | 部署的 API Base |
| api_provider | LLM API 提供商,用于提供商。例如 (azure, openai, vertex_ai) |
| hashed_api_key | 请求的哈希化 API 密钥 |
| api_key_alias | 使用的 API 密钥别名 |
| team | 请求的团队 |
| team_alias | 使用的团队别名 |
| exception_status | 异常状态,如果有的话 |
| exception_class | 异常类,如果有的话 |
成功与失败
| 指标名称 | 描述 |
|---|---|
litellm_deployment_success_responses | 部署成功的 LLM API 调用总数。标签: "requested_model", "litellm_model_name", "model_id", "api_base", "api_provider", "hashed_api_key", "api_key_alias", "team", "team_alias" |
litellm_deployment_failure_responses | 特定 LLM 部署失败的 LLM API 调用总数。标签: "requested_model", "litellm_model_name", "model_id", "api_base", "api_provider", "hashed_api_key", "api_key_alias", "team", "team_alias", "exception_status", "exception_class" |
litellm_deployment_total_requests | 部署的 LLM API 调用总数 - 成功 + 失败。标签: "requested_model", "litellm_model_name", "model_id", "api_base", "api_provider", "hashed_api_key", "api_key_alias", "team", "team_alias" |
剩余请求与 Token
| 指标名称 | 描述 |
|---|---|
litellm_remaining_requests_metric | 跟踪 LLM API 部署返回的 x-ratelimit-remaining-requests。标签: "model_group", "api_provider", "api_base", "litellm_model_name", "hashed_api_key", "api_key_alias" |
litellm_remaining_tokens | 跟踪 LLM API 部署返回的 x-ratelimit-remaining-tokens。标签: "model_group", "api_provider", "api_base", "litellm_model_name", "hashed_api_key", "api_key_alias" |
部署状态
| 指标名称 | 描述 |
|---|---|
litellm_deployment_state | 部署状态:0 = 健康,1 = 部分中断,2 = 完全中断。标签: "litellm_model_name", "model_id", "api_base", "api_provider" |
litellm_deployment_latency_per_output_token | 部署的每个输出 token 延迟。标签: "litellm_model_name", "model_id", "api_base", "api_provider", "hashed_api_key", "api_key_alias", "team", "team_alias" |
回退 (Failover) 指标
| 指标名称 | 描述 |
|---|---|
litellm_deployment_cooled_down | 部署被 LiteLLM 负载均衡逻辑冷却的次数。标签: "litellm_model_name", "model_id", "api_base", "api_provider", "exception_status" |
litellm_deployment_successful_fallbacks | 从主模型 -> 回退模型成功的请求回退次数。标签: "requested_model", "fallback_model", "hashed_api_key", "api_key_alias", "team", "team_alias", "exception_status", "exception_class" |
litellm_deployment_failed_fallbacks | 从主模型 -> 回退模型失败的请求回退次数。标签: "requested_model", "fallback_model", "hashed_api_key", "api_key_alias", "team", "team_alias", "exception_status", "exception_class" |
请求延迟指标
| 指标名称 | 描述 |
|---|---|
litellm_request_total_latency_metric | LiteLLM 代理服务器请求的总延迟(秒)- 跟踪标签 "end_user", "hashed_api_key", "api_key_alias", "requested_model", "team", "team_alias", "user", "model" |
litellm_overhead_latency_metric | LiteLLM 处理增加的延迟开销(秒)- 跟踪标签 "end_user", "hashed_api_key", "api_key_alias", "requested_model", "team", "team_alias", "user", "model" |
litellm_llm_api_latency_metric | 仅 LLM API 调用的延迟(秒)- 跟踪标签 "model", "hashed_api_key", "api_key_alias", "team", "team_alias", "requested_model", "end_user", "user" |
litellm_llm_api_time_to_first_token_metric | LLM API 调用到第一个 token 的时间 - 跟踪标签 model, hashed_api_key, api_key_alias, team, team_alias[注:仅为流式请求发出] |
[BETA]自定义指标
在 Prometheus 上跟踪上述所有事件的自定义指标。
- 在
config.yaml中定义自定义指标
model_list:
- model_name: openai/gpt-3.5-turbo
litellm_params:
model: openai/gpt-3.5-turbo
api_key: os.environ/OPENAI_API_KEY
litellm_settings:
callbacks: ["prometheus"]
custom_prometheus_metadata_labels: ["metadata.foo", "metadata.bar"]
- 使用自定义元数据标签发起请求
curl -L -X POST 'http://0.0.0.0:4000/v1/chat/completions' \
-H 'Content-Type: application/json' \
-H 'Authorization: Bearer <LITELLM_API_KEY>' \
-d '{
"model": "openai/gpt-3.5-turbo",
"messages": [
{
"role": "user",
"content": [
{
"type": "text",
"text": "What's in this image?"
}
]
}
],
"max_tokens": 300,
"metadata": {
"foo": "hello world"
}
}'
- 在你的
/metrics端点检查自定义指标
... "metadata_foo": "hello world" ...
监控系统健康状态
要监控 litellm 相关服务(redis / postgres)的健康状态,请执行
model_list:
- model_name: gpt-3.5-turbo
litellm_params:
model: gpt-3.5-turbo
litellm_settings:
service_callback: ["prometheus_system"]
| 指标名称 | 描述 |
|---|---|
litellm_redis_latency | redis 调用的直方图延迟 |
litellm_redis_fails | redis 调用失败次数 |
litellm_self_latency | 成功 litellm api 调用的直方图延迟 |
数据库事务队列健康指标
使用这些指标监控数据库事务队列的健康状态。例如,监控内存中和 redis 缓冲区的大小。
| 指标名称 | 描述 | 存储类型 |
|---|---|---|
litellm_pod_lock_manager_size | 指示哪个 pod 持有写入数据库更新的锁。 | Redis |
litellm_in_memory_daily_spend_update_queue_size | 内存中每日支出更新队列中的项目数。这些是每个用户的总支出日志。 | 内存中 (In-Memory) |
litellm_redis_daily_spend_update_queue_size | Redis 每日支出更新队列中的项目数。这些是每个用户的总支出日志。 | Redis |
litellm_in_memory_spend_update_queue_size | 密钥、用户、团队、团队成员等的内存中总支出值。 | 内存中 (In-Memory) |
litellm_redis_spend_update_queue_size | 密钥、用户、团队等的 Redis 总支出值。 | Redis |
🔥 LiteLLM 维护的 Grafana 面板
LiteLLM 维护的 Grafana 面板链接
https://github.com/BerriAI/litellm/tree/main/cookbook/litellm_proxy_server/grafana_dashboard
这是你可以使用 LiteLLM Grafana 面板监控的指标截图
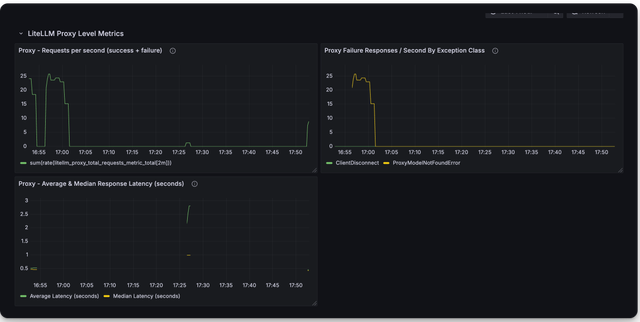
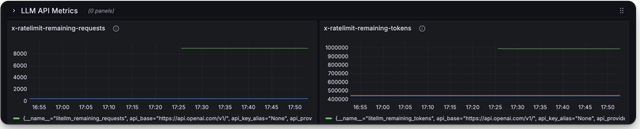

弃用指标
| 指标名称 | 描述 |
|---|---|
litellm_llm_api_failed_requests_metric | 已弃用 请使用 litellm_proxy_failed_requests_metric |
litellm_requests_metric | 已弃用 请使用 litellm_proxy_total_requests_metric |
在 /metrics 端点添加认证
默认情况下,/metrics 端点是未认证的。
你可以通过在配置中设置以下内容来选择在 /metrics 端点启用 litellm 认证
litellm_settings:
require_auth_for_metrics_endpoint: true
常见问题
_created 与 _total 指标有什么区别?
_created指标是在代理启动时创建的指标_total指标是每次请求时递增的指标
你应该使用 _total 指标进行计数