告警 / Webhooks
获取以下类型的告警
| 类别 | 告警类型 |
|---|---|
| LLM 性能 | 挂起的 API 调用、慢速 API 调用、失败的 API 调用、模型中断告警 |
| 预算与开销 | 按密钥/用户跟踪预算、软预算告警、按团队/标签的每周和每月开销报告 |
| 系统健康 | 数据库读写失败 |
| 每日报告 | 最慢的 5 个 LLM 部署、失败请求最多的 5 个 LLM 部署、按团队/标签的每周和每月开销 |
支持平台
快速入门
设置一个 Slack 告警通道以接收来自代理的告警。
步骤 1: 添加 Slack Webhook URL 到环境变量
从 https://api.slack.com/messaging/webhooks 获取 Slack webhook URL
您也可以使用 Discord Webhooks,请参阅此处
在您的代理环境变量中设置 SLACK_WEBHOOK_URL 以启用 Slack 告警。
export SLACK_WEBHOOK_URL="https://hooks.slack.com/services/<>/<>/<>"
步骤 2: 设置代理
general_settings:
alerting: ["slack"]
alerting_threshold: 300 # sends alerts if requests hang for 5min+ and responses take 5min+
spend_report_frequency: "1d" # [Optional] set as 1d, 2d, 30d .... Specify how often you want a Spend Report to be sent
# [OPTIONAL ALERTING ARGS]
alerting_args:
daily_report_frequency: 43200 # 12 hours in seconds
report_check_interval: 3600 # 1 hour in seconds
budget_alert_ttl: 86400 # 24 hours in seconds
outage_alert_ttl: 60 # 1 minute in seconds
region_outage_alert_ttl: 60 # 1 minute in seconds
minor_outage_alert_threshold: 5
major_outage_alert_threshold: 10
max_outage_alert_list_size: 1000
log_to_console: false
启动代理
$ litellm --config /path/to/config.yaml
步骤 3: 测试!
curl -X GET 'http://0.0.0.0:4000/health/services?service=slack' \
-H 'Authorization: Bearer sk-1234'
高级设置
从告警中屏蔽消息
默认情况下,告警会显示传递给 LLM 的 messages/input。如果您想在 Slack 告警中屏蔽此内容,请在配置中设置以下选项
general_settings:
alerting: ["slack"]
alert_types: ["spend_reports"]
litellm_settings:
redact_messages_in_exceptions: True
虚拟密钥的软预算告警
当密钥/团队的预算即将用尽时,使用此功能发送告警
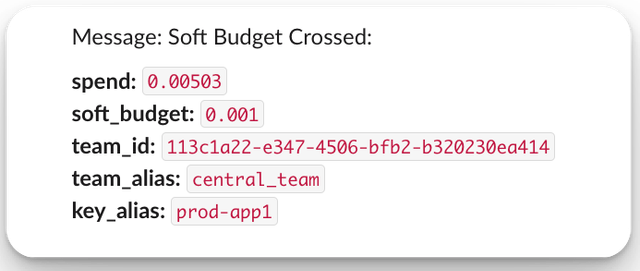
步骤 1. 创建一个带有软预算的虚拟密钥
将 soft_budget 设置为 0.001
curl -X 'POST' \
'https://:4000/key/generate' \
-H 'accept: application/json' \
-H 'x-goog-api-key: sk-1234' \
-H 'Content-Type: application/json' \
-d '{
"key_alias": "prod-app1",
"team_id": "113c1a22-e347-4506-bfb2-b320230ea414",
"soft_budget": 0.001
}'
步骤 2. 使用虚拟密钥向代理发送请求
curl http://0.0.0.0:4000/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer sk-Nb5eCf427iewOlbxXIH4Ow" \
-d '{
"model": "openai/gpt-4",
"messages": [
{
"role": "user",
"content": "this is a test request, write a short poem"
}
]
}'
步骤 3. 检查 Slack 是否收到预期告警
向告警添加元数据
向代理调用添加告警元数据以便调试。
import openai
client = openai.OpenAI(
api_key="anything",
base_url="http://0.0.0.0:4000"
)
# request sent to model set on litellm proxy, `litellm --model`
response = client.chat.completions.create(
model="gpt-3.5-turbo",
messages = [],
extra_body={
"metadata": {
"alerting_metadata": {
"hello": "world"
}
}
}
)
预期响应

选择特定的告警类型
如果您只想接收特定类型的告警,请设置 alert_types。如果未设置 alert_types,则启用所有默认告警类型。
general_settings:
alerting: ["slack"]
alert_types: [
"llm_exceptions",
"llm_too_slow",
"llm_requests_hanging",
"budget_alerts",
"spend_reports",
"db_exceptions",
"daily_reports",
"cooldown_deployment",
"new_model_added",
]
将 Slack 通道映射到告警类型
如果您想为每种告警类型设置特定的通道,请使用此功能
这使您可以进行以下操作
llm_exceptions -> go to slack channel #llm-exceptions
spend_reports -> go to slack channel #llm-spend-reports
在 config.yaml 中设置 alert_to_webhook_url
- 每个告警一个通道
- 每个告警多个通道
model_list:
- model_name: gpt-4
litellm_params:
model: openai/fake
api_key: fake-key
api_base: https://exampleopenaiendpoint-production.up.railway.app/
general_settings:
master_key: sk-1234
alerting: ["slack"]
alerting_threshold: 0.0001 # (Seconds) set an artificially low threshold for testing alerting
alert_to_webhook_url: {
"llm_exceptions": "https://hooks.slack.com/services/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",
"llm_too_slow": "https://hooks.slack.com/services/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",
"llm_requests_hanging": "https://hooks.slack.com/services/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",
"budget_alerts": "https://hooks.slack.com/services/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",
"db_exceptions": "https://hooks.slack.com/services/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",
"daily_reports": "https://hooks.slack.com/services/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",
"spend_reports": "https://hooks.slack.com/services/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",
"cooldown_deployment": "https://hooks.slack.com/services/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",
"new_model_added": "https://hooks.slack.com/services/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",
"outage_alerts": "https://hooks.slack.com/services/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",
}
litellm_settings:
success_callback: ["langfuse"]
为给定告警类型提供多个 Slack 通道
model_list:
- model_name: gpt-4
litellm_params:
model: openai/fake
api_key: fake-key
api_base: https://exampleopenaiendpoint-production.up.railway.app/
general_settings:
master_key: sk-1234
alerting: ["slack"]
alerting_threshold: 0.0001 # (Seconds) set an artificially low threshold for testing alerting
alert_to_webhook_url: {
"llm_exceptions": ["os.environ/SLACK_WEBHOOK_URL", "os.environ/SLACK_WEBHOOK_URL_2"],
"llm_too_slow": ["https://webhook.site/7843a980-a494-4967-80fb-d502dbc16886", "https://webhook.site/28cfb179-f4fb-4408-8129-729ff55cf213"],
"llm_requests_hanging": ["os.environ/SLACK_WEBHOOK_URL_5", "os.environ/SLACK_WEBHOOK_URL_6"],
"budget_alerts": ["os.environ/SLACK_WEBHOOK_URL_7", "os.environ/SLACK_WEBHOOK_URL_8"],
"db_exceptions": ["os.environ/SLACK_WEBHOOK_URL_9", "os.environ/SLACK_WEBHOOK_URL_10"],
"daily_reports": ["os.environ/SLACK_WEBHOOK_URL_11", "os.environ/SLACK_WEBHOOK_URL_12"],
"spend_reports": ["os.environ/SLACK_WEBHOOK_URL_13", "os.environ/SLACK_WEBHOOK_URL_14"],
"cooldown_deployment": ["os.environ/SLACK_WEBHOOK_URL_15", "os.environ/SLACK_WEBHOOK_URL_16"],
"new_model_added": ["os.environ/SLACK_WEBHOOK_URL_17", "os.environ/SLACK_WEBHOOK_URL_18"],
"outage_alerts": ["os.environ/SLACK_WEBHOOK_URL_19", "os.environ/SLACK_WEBHOOK_URL_20"],
}
litellm_settings:
success_callback: ["langfuse"]
测试 - 发送一个有效的 LLM 请求 - 预计会在其自己的 Slack 通道中看到 llm_too_slow 告警
curl -i https://:4000/v1/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer sk-1234" \
-d '{
"model": "gpt-4",
"messages": [
{"role": "user", "content": "Hello, Claude gm!"}
]
}'
MS Teams Webhooks
MS Teams 提供与 Slack 兼容的 webhook URL,可用于告警
快速入门
将其添加到您的 .env 文件中
SLACK_WEBHOOK_URL="https://berriai.webhook.office.com/webhookb2/...6901/IncomingWebhook/b55fa0c2a48647be8e6effedcd540266/e04b1092-4a3e-44a2-ab6b-29a0a4854d1d"
- 将其添加到您的 litellm 配置中
model_list:
model_name: "azure-model"
litellm_params:
model: "azure/gpt-35-turbo"
api_key: "my-bad-key" # 👈 bad key
general_settings:
alerting: ["slack"]
alerting_threshold: 300 # sends alerts if requests hang for 5min+ and responses take 5min+
- 运行健康检查!
调用代理的 /health/services 端点以测试您的告警连接是否正确设置。
curl --location 'http://0.0.0.0:4000/health/services?service=slack' \
--header 'Authorization: Bearer sk-1234'
预期响应
Discord Webhooks
Discord 提供与 Slack 兼容的 webhook URL,可用于告警
快速入门
获取您的 Discord 通道的 webhook URL
在您的 Discord webhook 后添加
/slack- 它应该看起来像
"https://discord.com/api/webhooks/1240030362193760286/cTLWt5ATn1gKmcy_982rl5xmYHsrM1IWJdmCL1AyOmU9JdQXazrp8L1_PYgUtgxj8x4f/slack"
- 将其添加到您的 litellm 配置中
model_list:
model_name: "azure-model"
litellm_params:
model: "azure/gpt-35-turbo"
api_key: "my-bad-key" # 👈 bad key
general_settings:
alerting: ["slack"]
alerting_threshold: 300 # sends alerts if requests hang for 5min+ and responses take 5min+
environment_variables:
SLACK_WEBHOOK_URL: "https://discord.com/api/webhooks/1240030362193760286/cTLWt5ATn1gKmcy_982rl5xmYHsrM1IWJdmCL1AyOmU9JdQXazrp8L1_PYgUtgxj8x4f/slack"
[BETA]预算告警的 Webhooks
注意: 这是一个 Beta 功能,因此规范可能会更改。
设置一个 webhook 以接收预算告警通知。
- 设置 config.yaml
将 URL 添加到您的环境变量,用于测试您可以使用此处的链接
export WEBHOOK_URL="https://webhook.site/6ab090e8-c55f-4a23-b075-3209f5c57906"
将 'webhook' 添加到 config.yaml
general_settings:
alerting: ["webhook"] # 👈 KEY CHANGE
- 启动代理
litellm --config /path/to/config.yaml
# RUNNING on http://0.0.0.0:4000
- 测试!
curl -X GET --location 'http://0.0.0.0:4000/health/services?service=webhook' \
--header 'Authorization: Bearer sk-1234'
预期响应
{
"spend": 1, # the spend for the 'event_group'
"max_budget": 0, # the 'max_budget' set for the 'event_group'
"token": "88dc28d0f030c55ed4ab77ed8faf098196cb1c05df778539800c9f1243fe6b4b",
"user_id": "default_user_id",
"team_id": null,
"user_email": null,
"key_alias": null,
"projected_exceeded_data": null,
"projected_spend": null,
"event": "budget_crossed", # Literal["budget_crossed", "threshold_crossed", "projected_limit_exceeded"]
"event_group": "user",
"event_message": "User Budget: Budget Crossed"
}
Webhook 事件的 API 规范
spendfloat: 'event_group' 的当前开销金额。max_budgetfloat 或 null: 'event_group' 的最大允许预算。如果未设置,则为 null。tokenstr: 密钥的哈希值,用于身份验证或识别目的。customer_idstr 或 null: 与事件关联的客户 ID (可选)。internal_user_idstr 或 null: 与事件关联的内部用户 ID (可选)。team_idstr 或 null: 与事件关联的团队 ID (可选)。user_emailstr 或 null: 与事件关联的内部用户的电子邮件 (可选)。key_aliasstr 或 null: 与事件关联的密钥别名 (可选)。projected_exceeded_datestr 或 null: 预计预算将超过的日期,当为密钥设置 'soft_budget' 时返回 (可选)。projected_spendfloat 或 null: 预计开销金额,当为密钥设置 'soft_budget' 时返回 (可选)。eventLiteral["budget_crossed", "threshold_crossed", "projected_limit_exceeded"]: 触发 webhook 的事件类型。可能的值为- "spend_tracked": 每当跟踪客户 ID 的开销时触发。
- "budget_crossed": 表示开销已超过最大预算。
- "threshold_crossed": 表示开销已达到阈值(当前在达到预算的 85% 和 95% 时发送)。
- "projected_limit_exceeded": 仅适用于“key” - 表示预计开销将超过软预算阈值。
event_groupLiteral["customer", "internal_user", "key", "team", "proxy"]: 与事件关联的组。可能的值为- "customer": 事件与特定客户相关
- "internal_user": 事件与特定内部用户相关。
- "key": 事件与特定密钥相关。
- "team": 事件与团队相关。
- "proxy": 事件与代理相关。
event_messagestr: 事件的人类可读描述。
区域中断告警 (✨ 企业版功能)
如果提供商区域发生中断,则设置告警。
general_settings:
alerting: ["slack"]
alert_types: ["region_outage_alerts"]
默认情况下,如果一个区域中的多个模型在 1 分钟内失败 5 个以上的请求,就会触发此告警。不计算 '400' 状态码错误(即 BadRequestErrors)。
使用以下参数控制阈值
general_settings:
alerting: ["slack"]
alert_types: ["region_outage_alerts"]
alerting_args:
region_outage_alert_ttl: 60 # time-window in seconds
minor_outage_alert_threshold: 5 # number of errors to trigger a minor alert
major_outage_alert_threshold: 10 # number of errors to trigger a major alert
所有可能的告警类型
LLM 相关告警
| 告警类型 | 描述 | 默认启用 |
|---|---|---|
llm_exceptions | LLM API 异常告警 | ✅ |
llm_too_slow | LLM 响应速度慢于设定阈值的通知 | ✅ |
llm_requests_hanging | LLM 请求未完成的告警 | ✅ |
cooldown_deployment | 部署进入冷却期时的告警 | ✅ |
new_model_added | 通过 /model/new 向 litellm 代理添加新模型时的通知 | ✅ |
outage_alerts | 特定 LLM 部署遇到中断时的告警 | ✅ |
region_outage_alerts | 特定 LLM 区域遇到中断时的告警。例如 us-east-1 | ✅ |
预算与开销告警
| 告警类型 | 描述 | 默认启用 |
|---|---|---|
budget_alerts | 与预算限制或阈值相关的通知 | ✅ |
spend_reports | 关于跨团队或标签开销的定期报告 | ✅ |
failed_tracking_spend | 开销跟踪失败时的告警 | ✅ |
daily_reports | 每日开销报告 | ✅ |
fallback_reports | 关于 LLM 回退发生情况的每周报告 | ✅ |
数据库告警
| 告警类型 | 描述 | 默认启用 |
|---|---|---|
db_exceptions | 数据库相关异常的通知 | ✅ |
管理端点告警 - 虚拟密钥、团队、内部用户
| 告警类型 | 描述 | 默认启用 |
|---|---|---|
new_virtual_key_created | 创建新虚拟密钥时的通知 | ❌ |
virtual_key_updated | 虚拟密钥修改时的告警 | ❌ |
virtual_key_deleted | 删除虚拟密钥时的通知 | ❌ |
new_team_created | 创建新团队的告警 | ❌ |
team_updated | 团队详情修改时的通知 | ❌ |
team_deleted | 团队删除时的告警 | ❌ |
new_internal_user_created | 新内部用户账户的通知 | ❌ |
internal_user_updated | 内部用户详情更改时的告警 | ❌ |
internal_user_deleted | 内部用户账户删除时的通知 | ❌ |
alerting_args 规范
| 参数 | 默认值 | 描述 |
|---|---|---|
daily_report_frequency | 43200 (12 小时) | 接收部署延迟/失败报告的频率(秒) |
report_check_interval | 3600 (1 小时) | 检查是否应发送报告的频率(后台进程,秒) |
budget_alert_ttl | 86400 (24 小时) | 预算告警的缓存 TTL,以防止预算超限时发送垃圾信息 |
outage_alert_ttl | 60 (1 分钟) | 收集模型中断错误的时间窗口(秒) |
region_outage_alert_ttl | 60 (1 分钟) | 收集基于区域的中断错误的时间窗口(秒) |
minor_outage_alert_threshold | 5 | 触发轻微中断告警的错误数量(不计算 400 错误) |
major_outage_alert_threshold | 10 | 触发严重中断告警的错误数量(不计算 400 错误) |
max_outage_alert_list_size | 1000 | 每个模型/区域缓存的最大错误数量 |
log_to_console | false | 如果为 true,则将告警 payload 作为 .warning 日志打印到控制台。 |