日志
使用以下方式记录代理的输入、输出和异常:
- Langfuse
- OpenTelemetry
- GCS、s3、Azure (Blob) 存储桶
- Lunary
- MLflow
- 自定义回调 - 自定义代码和 API 端点
- Langsmith
- DataDog
- DynamoDB
- 等
获取 LiteLLM 调用 ID
LiteLLM 为每个请求生成一个唯一的 call_id。这个 call_id 可用于在整个系统中跟踪请求。这对于在日志系统中(例如本页提到的任一系统)查找特定请求的信息非常有用。
curl -i -sSL --location 'http://0.0.0.0:4000/chat/completions' \
--header 'Authorization: Bearer sk-1234' \
--header 'Content-Type: application/json' \
--data '{
"model": "gpt-3.5-turbo",
"messages": [{"role": "user", "content": "what llm are you"}]
}' | grep 'x-litellm'
其输出为
x-litellm-call-id: b980db26-9512-45cc-b1da-c511a363b83f
x-litellm-model-id: cb41bc03f4c33d310019bae8c5afdb1af0a8f97b36a234405a9807614988457c
x-litellm-model-api-base: https://x-example-1234.openai.azure.com
x-litellm-version: 1.40.21
x-litellm-response-cost: 2.85e-05
x-litellm-key-tpm-limit: None
x-litellm-key-rpm-limit: None
其中一些请求头对于故障排除可能有用,但 x-litellm-call-id 对于在系统组件(包括日志工具)中跟踪请求最为有用。
日志功能
基于虚拟密钥和团队的条件日志记录
使用此功能可以
- 有条件地为某些虚拟密钥/团队启用日志记录
- 为不同的虚拟密钥/团队设置不同的日志提供商
编辑用户 API 密钥信息
从日志中编辑用户 API 密钥信息(哈希令牌、用户 ID、团队 ID 等)。
目前支持 Langfuse、OpenTelemetry、Logfire、ArizeAI 日志记录。
litellm_settings:
callbacks: ["langfuse"]
redact_user_api_key_info: true
编辑消息、响应内容
设置 litellm.turn_off_message_logging=True。这将阻止消息和响应记录到您的日志提供商,但请求元数据(例如支出)仍将被跟踪。
- 全局
- 按请求
1. 设置 config.yaml
model_list:
- model_name: gpt-3.5-turbo
litellm_params:
model: gpt-3.5-turbo
litellm_settings:
success_callback: ["langfuse"]
turn_off_message_logging: True # 👈 Key Change
2. 发送请求
curl --location 'http://0.0.0.0:4000/chat/completions' \
--header 'Content-Type: application/json' \
--data '{
"model": "gpt-3.5-turbo",
"messages": [
{
"role": "user",
"content": "what llm are you"
}
]
}'
动态请求消息编辑功能处于 BETA 阶段。
在请求头中传递一个值以启用单个请求的消息编辑功能。
x-litellm-enable-message-redaction: true
config.yaml 示例
1. 设置 config.yaml
model_list:
- model_name: gpt-3.5-turbo
litellm_params:
model: gpt-3.5-turbo
2. 设置按请求头
curl -L -X POST 'http://0.0.0.0:4000/v1/chat/completions' \
-H 'Content-Type: application/json' \
-H 'Authorization: Bearer sk-zV5HlSIm8ihj1F9C_ZbB1g' \
-H 'x-litellm-enable-message-redaction: true' \
-d '{
"model": "gpt-3.5-turbo-testing",
"messages": [
{
"role": "user",
"content": "Hey, how'\''s it going 1234?"
}
]
}'
3. 检查日志工具 + 支出日志
日志工具
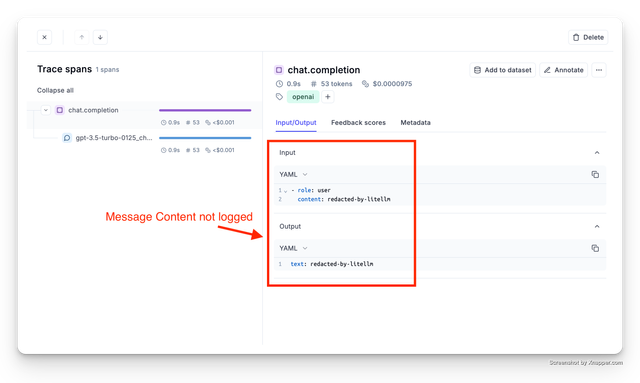
支出日志
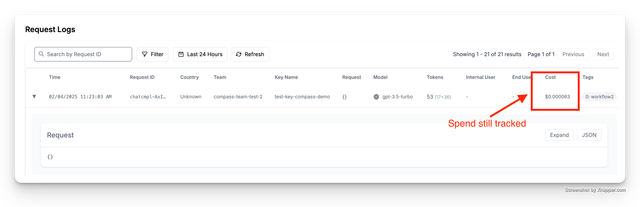
禁用消息编辑
如果您已开启 litellm.turn_on_message_logging,可以通过设置请求头 LiteLLM-Disable-Message-Redaction: true 来覆盖特定请求的设置。
curl --location 'http://0.0.0.0:4000/chat/completions' \
--header 'Content-Type: application/json' \
--header 'LiteLLM-Disable-Message-Redaction: true' \
--data '{
"model": "gpt-3.5-turbo",
"messages": [
{
"role": "user",
"content": "what llm are you"
}
]
}'
关闭所有跟踪/日志记录
在某些用例中,您可能希望关闭所有跟踪/日志记录。您可以通过在请求体中传递 no-log=True 来实现此目的。
通过在 config.yaml 文件中设置 global_disable_no_log_param:true 来禁用此功能。
litellm_settings:
global_disable_no_log_param: True
- Curl 请求
- OpenAI
curl -L -X POST 'http://0.0.0.0:4000/v1/chat/completions' \
-H 'Content-Type: application/json' \
-H 'Authorization: Bearer <litellm-api-key>' \
-d '{
"model": "openai/gpt-3.5-turbo",
"messages": [
{
"role": "user",
"content": [
{
"type": "text",
"text": "What'\''s in this image?"
}
]
}
],
"max_tokens": 300,
"no-log": true # 👈 Key Change
}'
import openai
client = openai.OpenAI(
api_key="anything",
base_url="http://0.0.0.0:4000"
)
# request sent to model set on litellm proxy, `litellm --model`
response = client.chat.completions.create(
model="gpt-3.5-turbo",
messages = [
{
"role": "user",
"content": "this is a test request, write a short poem"
}
],
extra_body={
"no-log": True # 👈 Key Change
}
)
print(response)
预期的控制台日志
LiteLLM.Info: "no-log request, skipping logging"
哪些内容会被记录?
可在 kwargs["standard_logging_object"] 下找到。这是一个标准负载,为每个响应记录。
Langfuse
我们将使用 --config 设置 litellm.success_callback = ["langfuse"],这将把所有成功的 LLM 调用记录到 Langfuse。请确保在您的环境中设置 LANGFUSE_PUBLIC_KEY 和 LANGFUSE_SECRET_KEY
步骤 1 安装 Langfuse
pip install langfuse>=2.0.0
步骤 2: 创建一个 config.yaml 文件并设置 litellm_settings: success_callback
model_list:
- model_name: gpt-3.5-turbo
litellm_params:
model: gpt-3.5-turbo
litellm_settings:
success_callback: ["langfuse"]
步骤 3: 设置记录到 Langfuse 所需的环境变量
export LANGFUSE_PUBLIC_KEY="pk_kk"
export LANGFUSE_SECRET_KEY="sk_ss"
# Optional, defaults to https://cloud.langfuse.com
export LANGFUSE_HOST="https://xxx.langfuse.com"
步骤 4: 启动代理,发起测试请求
启动代理
litellm --config config.yaml --debug
测试请求
litellm --test
Langfuse 上的预期输出

将元数据记录到 Langfuse
- Curl 请求
- OpenAI v1.0.0+
- Langchain
将 metadata 作为请求体的一部分传递
curl --location 'http://0.0.0.0:4000/chat/completions' \
--header 'Content-Type: application/json' \
--data '{
"model": "gpt-3.5-turbo",
"messages": [
{
"role": "user",
"content": "what llm are you"
}
],
"metadata": {
"generation_name": "ishaan-test-generation",
"generation_id": "gen-id22",
"trace_id": "trace-id22",
"trace_user_id": "user-id2"
}
}'
设置 extra_body={"metadata": { }} 为您想传递的 metadata
import openai
client = openai.OpenAI(
api_key="anything",
base_url="http://0.0.0.0:4000"
)
# request sent to model set on litellm proxy, `litellm --model`
response = client.chat.completions.create(
model="gpt-3.5-turbo",
messages = [
{
"role": "user",
"content": "this is a test request, write a short poem"
}
],
extra_body={
"metadata": {
"generation_name": "ishaan-generation-openai-client",
"generation_id": "openai-client-gen-id22",
"trace_id": "openai-client-trace-id22",
"trace_user_id": "openai-client-user-id2"
}
}
)
print(response)
from langchain.chat_models import ChatOpenAI
from langchain.prompts.chat import (
ChatPromptTemplate,
HumanMessagePromptTemplate,
SystemMessagePromptTemplate,
)
from langchain.schema import HumanMessage, SystemMessage
chat = ChatOpenAI(
openai_api_base="http://0.0.0.0:4000",
model = "gpt-3.5-turbo",
temperature=0.1,
extra_body={
"metadata": {
"generation_name": "ishaan-generation-langchain-client",
"generation_id": "langchain-client-gen-id22",
"trace_id": "langchain-client-trace-id22",
"trace_user_id": "langchain-client-user-id2"
}
}
)
messages = [
SystemMessage(
content="You are a helpful assistant that im using to make a test request to."
),
HumanMessage(
content="test from litellm. tell me why it's amazing in 1 sentence"
),
]
response = chat(messages)
print(response)
自定义标签
将 tags 作为请求体的一部分设置
- OpenAI Python v1.0.0+
- Curl 请求
- Langchain
import openai
client = openai.OpenAI(
api_key="sk-1234",
base_url="http://0.0.0.0:4000"
)
response = client.chat.completions.create(
model="llama3",
messages = [
{
"role": "user",
"content": "this is a test request, write a short poem"
}
],
user="palantir",
extra_body={
"metadata": {
"tags": ["jobID:214590dsff09fds", "taskName:run_page_classification"]
}
}
)
print(response)
将 metadata 作为请求体的一部分传递
curl --location 'http://0.0.0.0:4000/chat/completions' \
--header 'Content-Type: application/json' \
--header 'Authorization: Bearer sk-1234' \
--data '{
"model": "llama3",
"messages": [
{
"role": "user",
"content": "what llm are you"
}
],
"user": "palantir",
"metadata": {
"tags": ["jobID:214590dsff09fds", "taskName:run_page_classification"]
}
}'
from langchain.chat_models import ChatOpenAI
from langchain.prompts.chat import (
ChatPromptTemplate,
HumanMessagePromptTemplate,
SystemMessagePromptTemplate,
)
from langchain.schema import HumanMessage, SystemMessage
import os
os.environ["OPENAI_API_KEY"] = "sk-1234"
chat = ChatOpenAI(
openai_api_base="http://0.0.0.0:4000",
model = "llama3",
user="palantir",
extra_body={
"metadata": {
"tags": ["jobID:214590dsff09fds", "taskName:run_page_classification"]
}
}
)
messages = [
SystemMessage(
content="You are a helpful assistant that im using to make a test request to."
),
HumanMessage(
content="test from litellm. tell me why it's amazing in 1 sentence"
),
]
response = chat(messages)
print(response)
LiteLLM 标签 - cache_hit, cache_key
如果您想控制 LiteLLM 代理将哪些 LiteLLM 特定的字段作为标签记录,请使用此功能。默认情况下,LiteLLM 代理不记录 LiteLLM 特定的字段
| LiteLLM 特定字段 | 描述 | 示例值 |
|---|---|---|
cache_hit | 指示是否发生缓存命中 (True) 或未发生 (False) | true, false |
cache_key | 用于此请求的缓存密钥 | d2b758c**** |
proxy_base_url | 代理服务器的基础 URL,即您服务器上的环境变量 PROXY_BASE_URL 的值 | https://proxy.example.com |
user_api_key_alias | LiteLLM 虚拟密钥的别名。 | prod-app1 |
user_api_key_user_id | 与用户 API 密钥关联的唯一 ID。 | user_123, user_456 |
user_api_key_user_email | 与用户 API 密钥关联的电子邮件。 | user@example.com, admin@example.com |
user_api_key_team_alias | 与 API 密钥关联的团队的别名。 | team_alpha, dev_team |
用法
指定 langfuse_default_tags 来控制哪些 LiteLLM 字段被记录到 Langfuse
config.yaml 示例
model_list:
- model_name: gpt-4
litellm_params:
model: openai/fake
api_key: fake-key
api_base: https://exampleopenaiendpoint-production.up.railway.app/
litellm_settings:
success_callback: ["langfuse"]
# 👇 Key Change
langfuse_default_tags: ["cache_hit", "cache_key", "proxy_base_url", "user_api_key_alias", "user_api_key_user_id", "user_api_key_user_email", "user_api_key_team_alias", "semantic-similarity", "proxy_base_url"]
查看 LiteLLM 发送给提供商的 POST 请求
当您想查看 LiteLLM 发送给 LLM API 的原始 curl 请求时使用此功能
- Curl 请求
- OpenAI v1.0.0+
- Langchain
将 metadata 作为请求体的一部分传递
curl --location 'http://0.0.0.0:4000/chat/completions' \
--header 'Content-Type: application/json' \
--data '{
"model": "gpt-3.5-turbo",
"messages": [
{
"role": "user",
"content": "what llm are you"
}
],
"metadata": {
"log_raw_request": true
}
}'
设置 extra_body={"metadata": {"log_raw_request": True }} 为您想传递的 metadata
import openai
client = openai.OpenAI(
api_key="anything",
base_url="http://0.0.0.0:4000"
)
# request sent to model set on litellm proxy, `litellm --model`
response = client.chat.completions.create(
model="gpt-3.5-turbo",
messages = [
{
"role": "user",
"content": "this is a test request, write a short poem"
}
],
extra_body={
"metadata": {
"log_raw_request": True
}
}
)
print(response)
from langchain.chat_models import ChatOpenAI
from langchain.prompts.chat import (
ChatPromptTemplate,
HumanMessagePromptTemplate,
SystemMessagePromptTemplate,
)
from langchain.schema import HumanMessage, SystemMessage
chat = ChatOpenAI(
openai_api_base="http://0.0.0.0:4000",
model = "gpt-3.5-turbo",
temperature=0.1,
extra_body={
"metadata": {
"log_raw_request": True
}
}
)
messages = [
SystemMessage(
content="You are a helpful assistant that im using to make a test request to."
),
HumanMessage(
content="test from litellm. tell me why it's amazing in 1 sentence"
),
]
response = chat(messages)
print(response)
Langfuse 上的预期输出
您将在 Langfuse 元数据中看到 raw_request。这是 LiteLLM 发送给您的 LLM API 提供商的原始 CURL 命令
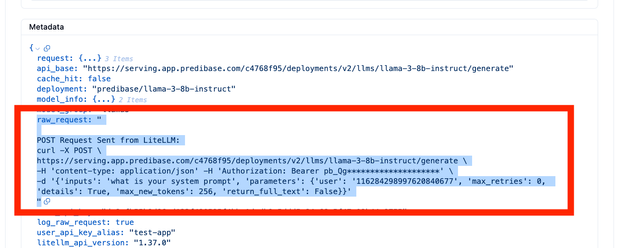
OpenTelemetry
[可选]通过在您的环境中设置以下变量来自定义 OTEL 服务名称和 OTEL TRACER 名称
OTEL_TRACER_NAME=<your-trace-name> # default="litellm"
OTEL_SERVICE_NAME=<your-service-name>` # default="litellm"
- 记录到控制台
- 记录到 Honeycomb
- 记录到 Traceloop Cloud
- 记录到 OTEL HTTP 收集器
- 记录到 OTEL GRPC 收集器
步骤 1: 设置回调和环境变量
将以下内容添加到您的环境变量中
OTEL_EXPORTER="console"
将 otel 添加到您的 litellm_config.yaml 作为回调
litellm_settings:
callbacks: ["otel"]
步骤 2: 启动代理,发起测试请求
启动代理
litellm --config config.yaml --detailed_debug
测试请求
curl --location 'http://0.0.0.0:4000/chat/completions' \
--header 'Content-Type: application/json' \
--data ' {
"model": "gpt-3.5-turbo",
"messages": [
{
"role": "user",
"content": "what llm are you"
}
]
}'
步骤 3: 期望在您的服务器日志/控制台中看到以下记录
这是 OTEL 日志记录的 Span
{
"name": "litellm-acompletion",
"context": {
"trace_id": "0x8d354e2346060032703637a0843b20a3",
"span_id": "0xd8d3476a2eb12724",
"trace_state": "[]"
},
"kind": "SpanKind.INTERNAL",
"parent_id": null,
"start_time": "2024-06-04T19:46:56.415888Z",
"end_time": "2024-06-04T19:46:56.790278Z",
"status": {
"status_code": "OK"
},
"attributes": {
"model": "llama3-8b-8192"
},
"events": [],
"links": [],
"resource": {
"attributes": {
"service.name": "litellm"
},
"schema_url": ""
}
}
快速入门 - 记录到 Honeycomb
步骤 1: 设置回调和环境变量
将以下内容添加到您的环境变量中
OTEL_EXPORTER="otlp_http"
OTEL_ENDPOINT="https://api.honeycomb.io/v1/traces"
OTEL_HEADERS="x-honeycomb-team=<your-api-key>"
将 otel 添加到您的 litellm_config.yaml 作为回调
litellm_settings:
callbacks: ["otel"]
步骤 2: 启动代理,发起测试请求
启动代理
litellm --config config.yaml --detailed_debug
测试请求
curl --location 'http://0.0.0.0:4000/chat/completions' \
--header 'Content-Type: application/json' \
--data ' {
"model": "gpt-3.5-turbo",
"messages": [
{
"role": "user",
"content": "what llm are you"
}
]
}'
快速入门 - 记录到 Traceloop
步骤 1: 将以下内容添加到您的环境变量中
OTEL_EXPORTER="otlp_http"
OTEL_ENDPOINT="https://api.traceloop.com"
OTEL_HEADERS="Authorization=Bearer%20<your-api-key>"
步骤 2: 将 otel 添加为回调
litellm_settings:
callbacks: ["otel"]
步骤 3: 启动代理,发起测试请求
启动代理
litellm --config config.yaml --detailed_debug
测试请求
curl --location 'http://0.0.0.0:4000/chat/completions' \
--header 'Content-Type: application/json' \
--data ' {
"model": "gpt-3.5-turbo",
"messages": [
{
"role": "user",
"content": "what llm are you"
}
]
}'
快速入门 - 记录到 OTEL Collector
步骤 1: 设置回调和环境变量
将以下内容添加到您的环境变量中
OTEL_EXPORTER="otlp_http"
OTEL_ENDPOINT="http://0.0.0.0:4317"
OTEL_HEADERS="x-honeycomb-team=<your-api-key>" # Optional
将 otel 添加到您的 litellm_config.yaml 作为回调
litellm_settings:
callbacks: ["otel"]
步骤 2: 启动代理,发起测试请求
启动代理
litellm --config config.yaml --detailed_debug
测试请求
curl --location 'http://0.0.0.0:4000/chat/completions' \
--header 'Content-Type: application/json' \
--data ' {
"model": "gpt-3.5-turbo",
"messages": [
{
"role": "user",
"content": "what llm are you"
}
]
}'
快速入门 - 记录到 OTEL GRPC Collector
步骤 1: 设置回调和环境变量
将以下内容添加到您的环境变量中
OTEL_EXPORTER="otlp_grpc"
OTEL_ENDPOINT="http:/0.0.0.0:4317"
OTEL_HEADERS="x-honeycomb-team=<your-api-key>" # Optional
将 otel 添加到您的 litellm_config.yaml 作为回调
litellm_settings:
callbacks: ["otel"]
步骤 2: 启动代理,发起测试请求
启动代理
litellm --config config.yaml --detailed_debug
测试请求
curl --location 'http://0.0.0.0:4000/chat/completions' \
--header 'Content-Type: application/json' \
--data ' {
"model": "gpt-3.5-turbo",
"messages": [
{
"role": "user",
"content": "what llm are you"
}
]
}'
🎉 期望在您的 OTEL 收集器中看到此跟踪记录
编辑消息、响应内容
为 otel 设置 message_logging=False,将不会记录消息/响应
litellm_settings:
callbacks: ["otel"]
## 👇 Key Change
callback_settings:
otel:
message_logging: False
Traceparent 请求头
跨服务的上下文传播 Traceparent HTTP Header
❓ 当您想在分布式跟踪系统中传递有关传入请求的信息时使用此功能
✅ 关键变化:在您的请求中传递 traceparent 请求头。在此处阅读有关 traceparent 请求头的更多信息
traceparent: 00-80e1afed08e019fc1110464cfa66635c-7a085853722dc6d2-01
示例用法
- 向 LiteLLM 代理发起带有
traceparent请求头的请求
import openai
import uuid
client = openai.OpenAI(api_key="sk-1234", base_url="http://0.0.0.0:4000")
example_traceparent = f"00-80e1afed08e019fc1110464cfa66635c-02e80198930058d4-01"
extra_headers = {
"traceparent": example_traceparent
}
_trace_id = example_traceparent.split("-")[1]
print("EXTRA HEADERS: ", extra_headers)
print("Trace ID: ", _trace_id)
response = client.chat.completions.create(
model="llama3",
messages=[
{"role": "user", "content": "this is a test request, write a short poem"}
],
extra_headers=extra_headers,
)
print(response)
# EXTRA HEADERS: {'traceparent': '00-80e1afed08e019fc1110464cfa66635c-02e80198930058d4-01'}
# Trace ID: 80e1afed08e019fc1110464cfa66635c
- 在 OTEL Logger 上查找跟踪 ID
在您的 OTEL Collector 上搜索 Trace=80e1afed08e019fc1110464cfa66635c

将 Traceparent HTTP Header 转发到 LLM API
如果您想将 traceparent 请求头转发到您自托管的 LLM(例如 vLLM),请使用此功能
在您的 config.yaml 中设置 forward_traceparent_to_llm_provider: True。这将把 traceparent 请求头转发到您的 LLM API
仅将其用于自托管的 LLM,这可能导致 Bedrock、VertexAI 调用失败
litellm_settings:
forward_traceparent_to_llm_provider: True
Google Cloud Storage 存储桶
将 LLM 日志记录到 Google Cloud Storage 存储桶
✨ 这是企业版专属功能 在此处开始使用企业版
| 属性 | 详情 |
|---|---|
| 描述 | 将 LLM 输入/输出记录到云存储桶 |
| 负载测试基准 | 基准测试 |
| 关于 Cloud Storage 的 Google 文档 | Google Cloud Storage |
用法
- 将
gcs_bucket添加到 LiteLLM Config.yaml
model_list:
- litellm_params:
api_base: https://exampleopenaiendpoint-production.up.railway.app/
api_key: my-fake-key
model: openai/my-fake-model
model_name: fake-openai-endpoint
litellm_settings:
callbacks: ["gcs_bucket"] # 👈 KEY CHANGE # 👈 KEY CHANGE
- 设置所需的环境变量
GCS_BUCKET_NAME="<your-gcs-bucket-name>"
GCS_PATH_SERVICE_ACCOUNT="/Users/ishaanjaffer/Downloads/adroit-crow-413218-a956eef1a2a8.json" # Add path to service account.json
- 启动代理
litellm --config /path/to/config.yaml
- 测试一下!
curl --location 'http://0.0.0.0:4000/chat/completions' \
--header 'Content-Type: application/json' \
--data ' {
"model": "fake-openai-endpoint",
"messages": [
{
"role": "user",
"content": "what llm are you"
}
],
}
'
GCS 存储桶上的预期日志
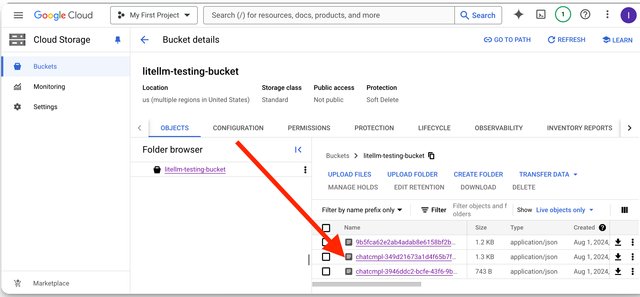
GCS 存储桶上记录的字段
从 Google Cloud Console 获取 service_account.json
- 前往 Google Cloud Console
- 搜索 IAM 与管理员
- 点击服务账号
- 选择一个服务账号
- 点击“密钥” -> 添加密钥 -> 创建新密钥 -> JSON
- 保存 JSON 文件并将路径添加到
GCS_PATH_SERVICE_ACCOUNT
Google Cloud Storage - PubSub 主题
将 LLM 日志/支出日志记录到 Google Cloud Storage PubSub 主题
✨ 这是企业版专属功能 在此处开始使用企业版
| 属性 | 详情 |
|---|---|
| 描述 | 将 LiteLLM SpendLogs Table 记录到 Google Cloud Storage PubSub 主题 |
何时使用 gcs_pubsub?
- 如果您的 LiteLLM 数据库的支出日志已超过 100 万条,并且您想将
SpendLogs发送到可由 GCS BigQuery 消费的 PubSub 主题
用法
- 将
gcs_pubsub添加到 LiteLLM Config.yaml
model_list:
- litellm_params:
api_base: https://exampleopenaiendpoint-production.up.railway.app/
api_key: my-fake-key
model: openai/my-fake-model
model_name: fake-openai-endpoint
litellm_settings:
callbacks: ["gcs_pubsub"] # 👈 KEY CHANGE # 👈 KEY CHANGE
- 设置所需的环境变量
GCS_PUBSUB_TOPIC_ID="litellmDB"
GCS_PUBSUB_PROJECT_ID="reliableKeys"
- 启动代理
litellm --config /path/to/config.yaml
- 测试一下!
curl --location 'http://0.0.0.0:4000/chat/completions' \
--header 'Content-Type: application/json' \
--data ' {
"model": "fake-openai-endpoint",
"messages": [
{
"role": "user",
"content": "what llm are you"
}
],
}
'
s3 存储桶
我们将使用 --config 来设置
litellm.success_callback = ["s3"]
这将把所有成功的 LLM 调用记录到 s3 存储桶
步骤 1 在 .env 中设置 AWS 凭据
AWS_ACCESS_KEY_ID = ""
AWS_SECRET_ACCESS_KEY = ""
AWS_REGION_NAME = ""
步骤 2: 创建一个 config.yaml 文件并设置 litellm_settings: success_callback
model_list:
- model_name: gpt-3.5-turbo
litellm_params:
model: gpt-3.5-turbo
litellm_settings:
success_callback: ["s3"]
s3_callback_params:
s3_bucket_name: logs-bucket-litellm # AWS Bucket Name for S3
s3_region_name: us-west-2 # AWS Region Name for S3
s3_aws_access_key_id: os.environ/AWS_ACCESS_KEY_ID # us os.environ/<variable name> to pass environment variables. This is AWS Access Key ID for S3
s3_aws_secret_access_key: os.environ/AWS_SECRET_ACCESS_KEY # AWS Secret Access Key for S3
s3_path: my-test-path # [OPTIONAL] set path in bucket you want to write logs to
s3_endpoint_url: https://s3.amazonaws.com # [OPTIONAL] S3 endpoint URL, if you want to use Backblaze/cloudflare s3 buckets
步骤 3: 启动代理,发起测试请求
启动代理
litellm --config config.yaml --debug
测试请求
curl --location 'http://0.0.0.0:4000/chat/completions' \
--header 'Content-Type: application/json' \
--data ' {
"model": "Azure OpenAI GPT-4 East",
"messages": [
{
"role": "user",
"content": "what llm are you"
}
]
}'
您的日志应可在指定的 s3 存储桶中找到
对象键中的团队别名前缀
这是一个预览功能
您可以通过在 config.yaml 文件中设置 team_alias 将团队别名添加到对象键。这将使用团队别名作为对象键的前缀。
litellm_settings:
callbacks: ["s3"]
enable_preview_features: true
s3_callback_params:
s3_bucket_name: logs-bucket-litellm
s3_region_name: us-west-2
s3_aws_access_key_id: os.environ/AWS_ACCESS_KEY_ID
s3_aws_secret_access_key: os.environ/AWS_SECRET_ACCESS_KEY
s3_path: my-test-path
s3_endpoint_url: https://s3.amazonaws.com
s3_use_team_prefix: true
在 s3 存储桶中,您将看到对象键为 my-test-path/my-team-alias/...
Azure Blob 存储
将 LLM 日志记录到 Azure Data Lake Storage
✨ 这是企业版专属功能 在此处开始使用企业版
| 属性 | 详情 |
|---|---|
| 描述 | 将 LLM 输入/输出记录到 Azure Blob 存储(存储桶) |
| 关于 Data Lake Storage 的 Azure 文档 | Azure Data Lake Storage |
用法
- 将
azure_storage添加到 LiteLLM Config.yaml
model_list:
- model_name: fake-openai-endpoint
litellm_params:
model: openai/fake
api_key: fake-key
api_base: https://exampleopenaiendpoint-production.up.railway.app/
litellm_settings:
callbacks: ["azure_storage"] # 👈 KEY CHANGE # 👈 KEY CHANGE
- 设置所需的环境变量
# Required Environment Variables for Azure Storage
AZURE_STORAGE_ACCOUNT_NAME="litellm2" # The name of the Azure Storage Account to use for logging
AZURE_STORAGE_FILE_SYSTEM="litellm-logs" # The name of the Azure Storage File System to use for logging. (Typically the Container name)
# Authentication Variables
# Option 1: Use Storage Account Key
AZURE_STORAGE_ACCOUNT_KEY="xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx" # The Azure Storage Account Key to use for Authentication
# Option 2: Use Tenant ID + Client ID + Client Secret
AZURE_STORAGE_TENANT_ID="985efd7cxxxxxxxxxx" # The Application Tenant ID to use for Authentication
AZURE_STORAGE_CLIENT_ID="abe66585xxxxxxxxxx" # The Application Client ID to use for Authentication
AZURE_STORAGE_CLIENT_SECRET="uMS8Qxxxxxxxxxx" # The Application Client Secret to use for Authentication
- 启动代理
litellm --config /path/to/config.yaml
- 测试一下!
curl --location 'http://0.0.0.0:4000/chat/completions' \
--header 'Content-Type: application/json' \
--data ' {
"model": "fake-openai-endpoint",
"messages": [
{
"role": "user",
"content": "what llm are you"
}
],
}
'
Azure Data Lake Storage 上的预期日志
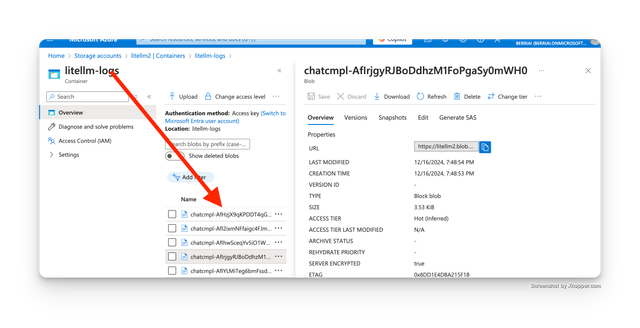
Azure Data Lake Storage 上记录的字段
标准日志对象将记录到 Azure Data Lake Storage
DataDog
LiteLLM 支持记录到以下 Datadog 集成
datadogDatadog Logsdatadog_llm_observabilityDatadog LLM 可观测性ddtrace-runDatadog Tracing
- Datadog Logs
- Datadog LLM 可观测性
我们将使用 --config 设置 litellm.callbacks = ["datadog"],这将把所有成功的 LLM 调用记录到 DataDog
步骤 1: 创建一个 config.yaml 文件并设置 litellm_settings: success_callback
model_list:
- model_name: gpt-3.5-turbo
litellm_params:
model: gpt-3.5-turbo
litellm_settings:
callbacks: ["datadog"] # logs llm success + failure logs on datadog
service_callback: ["datadog"] # logs redis, postgres failures on datadog
model_list:
- model_name: gpt-3.5-turbo
litellm_params:
model: gpt-3.5-turbo
litellm_settings:
callbacks: ["datadog_llm_observability"] # logs llm success logs on datadog
步骤 2: 设置 Datadog 所需的环境变量
DD_API_KEY="5f2d0f310***********" # your datadog API Key
DD_SITE="us5.datadoghq.com" # your datadog base url
DD_SOURCE="litellm_dev" # [OPTIONAL] your datadog source. use to differentiate dev vs. prod deployments
步骤 3: 启动代理,发起测试请求
启动代理
litellm --config config.yaml --debug
测试请求
curl --location 'http://0.0.0.0:4000/chat/completions' \
--header 'Content-Type: application/json' \
--data '{
"model": "gpt-3.5-turbo",
"messages": [
{
"role": "user",
"content": "what llm are you"
}
],
"metadata": {
"your-custom-metadata": "custom-field",
}
}'
Datadog 上的预期输出
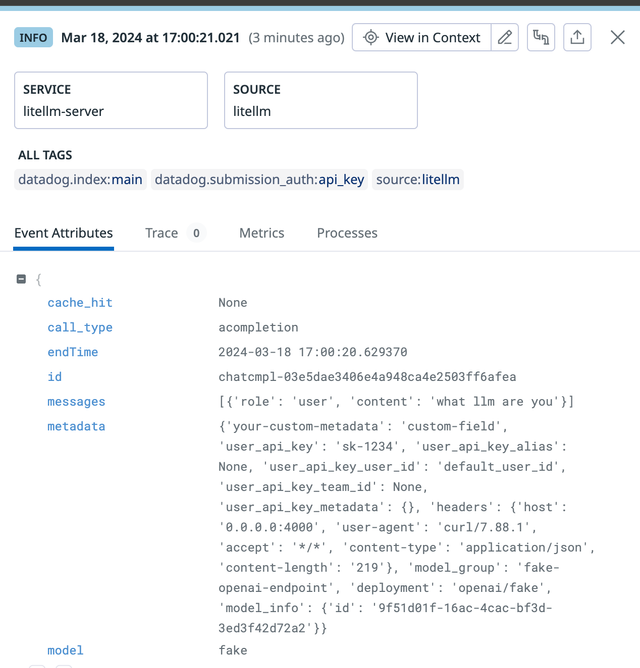
Datadog Tracing
使用 ddtrace-run 在 LiteLLM 代理上启用 Datadog Tracing
将 USE_DDTRACE=true 传递给 docker run 命令。当 USE_DDTRACE=true 时,代理将运行 ddtrace-run litellm 作为 ENTRYPOINT,而不是仅仅运行 litellm
docker run \
-v $(pwd)/litellm_config.yaml:/app/config.yaml \
-e USE_DDTRACE=true \
-p 4000:4000 \
ghcr.io/berriai/litellm:main-latest \
--config /app/config.yaml --detailed_debug
设置 DD 变量(例如 DD_SERVICE)
LiteLLM 支持自定义以下 Datadog 环境变量
| 环境变量 | 描述 | 默认值 | 必需 |
|---|---|---|---|
DD_API_KEY | 您的 Datadog API 密钥,用于身份验证 | 无 | ✅ 是 |
DD_SITE | 您的 Datadog 站点(例如,“us5.datadoghq.com”) | 无 | ✅ 是 |
DD_ENV | 您的日志的环境标签(例如,“production”,“staging”) | "unknown" | ❌ 否 |
DD_SERVICE | 您的日志的服务名称 | "litellm-server" | ❌ 否 |
DD_SOURCE | 您的日志的源名称 | "litellm" | ❌ 否 |
DD_VERSION | 您的日志的版本标签 | "unknown" | ❌ 否 |
HOSTNAME | 您的日志的主机名标签 | "" | ❌ 否 |
POD_NAME | Pod 名称标签(对 Kubernetes 部署有用) | "unknown" | ❌ 否 |
Lunary
步骤 1: 安装依赖项并设置您的环境变量
安装依赖项
pip install litellm lunary
从 https://app.lunary.ai/settings 获取您的 Lunary 公钥
export LUNARY_PUBLIC_KEY="<your-public-key>"
步骤 2: 创建一个 config.yaml 并设置 lunary 回调
model_list:
- model_name: "*"
litellm_params:
model: "*"
litellm_settings:
success_callback: ["lunary"]
failure_callback: ["lunary"]
步骤 3: 启动 LiteLLM 代理
litellm --config config.yaml
步骤 4: 发起请求
curl -X POST 'http://0.0.0.0:4000/chat/completions' \
-H 'Content-Type: application/json' \
-d '{
"model": "gpt-4o",
"messages": [
{
"role": "system",
"content": "You are a helpful math tutor. Guide the user through the solution step by step."
},
{
"role": "user",
"content": "how can I solve 8x + 7 = -23"
}
]
}'
MLflow
步骤 1: 安装依赖项
安装依赖项。
pip install litellm mlflow
步骤 2: 创建一个带有 mlflow 回调的 config.yaml
model_list:
- model_name: "*"
litellm_params:
model: "*"
litellm_settings:
success_callback: ["mlflow"]
failure_callback: ["mlflow"]
步骤 3: 启动 LiteLLM 代理
litellm --config config.yaml
步骤 4: 发起请求
curl -X POST 'http://0.0.0.0:4000/chat/completions' \
-H 'Content-Type: application/json' \
-d '{
"model": "gpt-4o-mini",
"messages": [
{
"role": "user",
"content": "What is the capital of France?"
}
]
}'
步骤 5: 查看跟踪
运行以下命令启动 MLflow UI 并查看记录的跟踪。
mlflow ui
自定义回调类[异步]
当您想在 python 中运行自定义回调时使用此功能
步骤 1 - 创建您的自定义 litellm 回调类
我们为此使用了 litellm.integrations.custom_logger,有关 LiteLLM 自定义回调的更多详情请参见 此处
在 python 文件中定义您的自定义回调类。
这是一个用于跟踪 key, user, model, prompt, response, tokens, cost 的自定义记录器示例。我们创建一个名为 custom_callbacks.py 的文件并初始化 proxy_handler_instance
from litellm.integrations.custom_logger import CustomLogger
import litellm
# This file includes the custom callbacks for LiteLLM Proxy
# Once defined, these can be passed in proxy_config.yaml
class MyCustomHandler(CustomLogger):
def log_pre_api_call(self, model, messages, kwargs):
print(f"Pre-API Call")
def log_post_api_call(self, kwargs, response_obj, start_time, end_time):
print(f"Post-API Call")
def log_success_event(self, kwargs, response_obj, start_time, end_time):
print("On Success")
def log_failure_event(self, kwargs, response_obj, start_time, end_time):
print(f"On Failure")
async def async_log_success_event(self, kwargs, response_obj, start_time, end_time):
print(f"On Async Success!")
# log: key, user, model, prompt, response, tokens, cost
# Access kwargs passed to litellm.completion()
model = kwargs.get("model", None)
messages = kwargs.get("messages", None)
user = kwargs.get("user", None)
# Access litellm_params passed to litellm.completion(), example access `metadata`
litellm_params = kwargs.get("litellm_params", {})
metadata = litellm_params.get("metadata", {}) # headers passed to LiteLLM proxy, can be found here
# Calculate cost using litellm.completion_cost()
cost = litellm.completion_cost(completion_response=response_obj)
response = response_obj
# tokens used in response
usage = response_obj["usage"]
print(
f"""
Model: {model},
Messages: {messages},
User: {user},
Usage: {usage},
Cost: {cost},
Response: {response}
Proxy Metadata: {metadata}
"""
)
return
async def async_log_failure_event(self, kwargs, response_obj, start_time, end_time):
try:
print(f"On Async Failure !")
print("\nkwargs", kwargs)
# Access kwargs passed to litellm.completion()
model = kwargs.get("model", None)
messages = kwargs.get("messages", None)
user = kwargs.get("user", None)
# Access litellm_params passed to litellm.completion(), example access `metadata`
litellm_params = kwargs.get("litellm_params", {})
metadata = litellm_params.get("metadata", {}) # headers passed to LiteLLM proxy, can be found here
# Access Exceptions & Traceback
exception_event = kwargs.get("exception", None)
traceback_event = kwargs.get("traceback_exception", None)
# Calculate cost using litellm.completion_cost()
cost = litellm.completion_cost(completion_response=response_obj)
print("now checking response obj")
print(
f"""
Model: {model},
Messages: {messages},
User: {user},
Cost: {cost},
Response: {response_obj}
Proxy Metadata: {metadata}
Exception: {exception_event}
Traceback: {traceback_event}
"""
)
except Exception as e:
print(f"Exception: {e}")
proxy_handler_instance = MyCustomHandler()
# Set litellm.callbacks = [proxy_handler_instance] on the proxy
# need to set litellm.callbacks = [proxy_handler_instance] # on the proxy
步骤 2 - 在 config.yaml 中传递您的自定义回调类
我们将 步骤 1 中定义的自定义回调类传递给 config.yaml。将 callbacks 设置为 python_filename.logger_instance_name
在下面的配置中,我们传递了
- python_filename:
custom_callbacks.py - logger_instance_name:
proxy_handler_instance。这在步骤 1 中定义
callbacks: custom_callbacks.proxy_handler_instance
model_list:
- model_name: gpt-3.5-turbo
litellm_params:
model: gpt-3.5-turbo
litellm_settings:
callbacks: custom_callbacks.proxy_handler_instance # sets litellm.callbacks = [proxy_handler_instance]
步骤 3 - 启动代理 + 测试请求
litellm --config proxy_config.yaml
curl --location 'http://0.0.0.0:4000/chat/completions' \
--header 'Authorization: Bearer sk-1234' \
--data ' {
"model": "gpt-3.5-turbo",
"messages": [
{
"role": "user",
"content": "good morning good sir"
}
],
"user": "ishaan-app",
"temperature": 0.2
}'
代理上的结果日志
On Success
Model: gpt-3.5-turbo,
Messages: [{'role': 'user', 'content': 'good morning good sir'}],
User: ishaan-app,
Usage: {'completion_tokens': 10, 'prompt_tokens': 11, 'total_tokens': 21},
Cost: 3.65e-05,
Response: {'id': 'chatcmpl-8S8avKJ1aVBg941y5xzGMSKrYCMvN', 'choices': [{'finish_reason': 'stop', 'index': 0, 'message': {'content': 'Good morning! How can I assist you today?', 'role': 'assistant'}}], 'created': 1701716913, 'model': 'gpt-3.5-turbo-0613', 'object': 'chat.completion', 'system_fingerprint': None, 'usage': {'completion_tokens': 10, 'prompt_tokens': 11, 'total_tokens': 21}}
Proxy Metadata: {'user_api_key': None, 'headers': Headers({'host': '0.0.0.0:4000', 'user-agent': 'curl/7.88.1', 'accept': '*/*', 'authorization': 'Bearer sk-1234', 'content-length': '199', 'content-type': 'application/x-www-form-urlencoded'}), 'model_group': 'gpt-3.5-turbo', 'deployment': 'gpt-3.5-turbo-ModelID-gpt-3.5-turbo'}
记录代理请求对象、请求头、URL
您可以按照以下方式访问发送到代理的每个请求的 url、headers、request body
class MyCustomHandler(CustomLogger):
async def async_log_success_event(self, kwargs, response_obj, start_time, end_time):
print(f"On Async Success!")
litellm_params = kwargs.get("litellm_params", None)
proxy_server_request = litellm_params.get("proxy_server_request")
print(proxy_server_request)
预期输出
{
"url": "http://testserver/chat/completions",
"method": "POST",
"headers": {
"host": "testserver",
"accept": "*/*",
"accept-encoding": "gzip, deflate",
"connection": "keep-alive",
"user-agent": "testclient",
"authorization": "Bearer None",
"content-length": "105",
"content-type": "application/json"
},
"body": {
"model": "Azure OpenAI GPT-4 Canada",
"messages": [
{
"role": "user",
"content": "hi"
}
],
"max_tokens": 10
}
}
记录在 config.yaml 中设置的 model_info
以下是如何记录在您的代理 config.yaml 中设置的 model_info。关于在 config.yaml 中设置 model_info 的信息
class MyCustomHandler(CustomLogger):
async def async_log_success_event(self, kwargs, response_obj, start_time, end_time):
print(f"On Async Success!")
litellm_params = kwargs.get("litellm_params", None)
model_info = litellm_params.get("model_info")
print(model_info)
预期输出
{'mode': 'embedding', 'input_cost_per_token': 0.002}
记录来自代理的响应
/chat/completions 和 /embeddings 的响应都可以作为 response_obj 使用
注意:对于 /chat/completions,stream=True 和 非流式 响应都可以作为 response_obj 使用
class MyCustomHandler(CustomLogger):
async def async_log_success_event(self, kwargs, response_obj, start_time, end_time):
print(f"On Async Success!")
print(response_obj)
预期输出 /chat/completion[适用于 流式 和 非流式 响应]
ModelResponse(
id='chatcmpl-8Tfu8GoMElwOZuj2JlHBhNHG01PPo',
choices=[
Choices(
finish_reason='stop',
index=0,
message=Message(
content='As an AI language model, I do not have a physical body and therefore do not possess any degree or educational qualifications. My knowledge and abilities come from the programming and algorithms that have been developed by my creators.',
role='assistant'
)
)
],
created=1702083284,
model='chatgpt-v-2',
object='chat.completion',
system_fingerprint=None,
usage=Usage(
completion_tokens=42,
prompt_tokens=5,
total_tokens=47
)
)
预期输出 /embeddings
{
'model': 'ada',
'data': [
{
'embedding': [
-0.035126980394124985, -0.020624293014407158, -0.015343423001468182,
-0.03980357199907303, -0.02750781551003456, 0.02111034281551838,
-0.022069307044148445, -0.019442008808255196, -0.00955679826438427,
-0.013143060728907585, 0.029583381488919258, -0.004725852981209755,
-0.015198921784758568, -0.014069183729588985, 0.00897879246622324,
0.01521205808967352,
# ... (truncated for brevity)
]
}
]
}
自定义回调 API[异步]
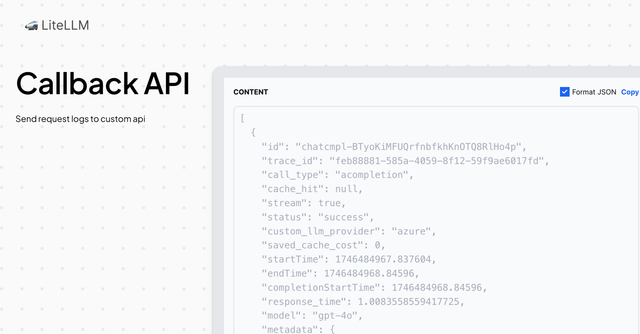
将 LiteLLM 日志发送到自定义 API 端点
这是企业版专属功能 在此处开始使用企业版
| 属性 | 详情 |
|---|---|
| 描述 | 将 LLM 输入/输出记录到自定义 API 端点 |
| 记录的负载 | List[StandardLoggingPayload] LiteLLM 将 StandardLoggingPayload 对象列表记录到您的端点 |
如果您希望,可以使用此功能
- 使用非 Python 编程语言编写的自定义回调
- 让您的回调在不同的微服务上运行
用法
- 在 LiteLLM config.yaml 中设置
success_callback: ["generic_api"]
model_list:
- model_name: openai/gpt-4o
litellm_params:
model: openai/gpt-4o
api_key: os.environ/OPENAI_API_KEY
litellm_settings:
success_callback: ["generic_api"]
- 为自定义 API 端点设置环境变量
| 环境变量 | 详情 | 必需 |
|---|---|---|
GENERIC_LOGGER_ENDPOINT | 我们应该发送回调日志的端点 + 路由 | 是 |
GENERIC_LOGGER_HEADERS | 可选:设置要发送到自定义 API 端点的请求头 | 否,这是可选的 |
GENERIC_LOGGER_ENDPOINT="https://webhook-test.com/30343bc33591bc5e6dc44217ceae3e0a"
# Optional: Set headers to be sent to the custom API endpoint
GENERIC_LOGGER_HEADERS="Authorization=Bearer <your-api-key>"
# if multiple headers, separate by commas
GENERIC_LOGGER_HEADERS="Authorization=Bearer <your-api-key>,X-Custom-Header=custom-header-value"
- 启动代理
litellm --config /path/to/config.yaml
- 发起测试请求
curl -i --location 'http://0.0.0.0:4000/chat/completions' \
--header 'Content-Type: application/json' \
--header 'Authorization: Bearer sk-1234' \
--data '{
"model": "openai/gpt-4o",
"messages": [
{
"role": "user",
"content": "what llm are you"
}
]
}'
Langsmith
- 在 LiteLLM config.yaml 中设置
success_callback: ["langsmith"]
如果您使用的是自定义 LangSmith 实例,可以将 LANGSMITH_BASE_URL 环境变量设置为指向您的实例。
litellm_settings:
success_callback: ["langsmith"]
environment_variables:
LANGSMITH_API_KEY: "lsv2_pt_xxxxxxxx"
LANGSMITH_PROJECT: "litellm-proxy"
LANGSMITH_BASE_URL: "https://api.smith.langchain.com" # (Optional - only needed if you have a custom Langsmith instance)
- 启动代理
litellm --config /path/to/config.yaml
- 测试一下!
curl --location 'http://0.0.0.0:4000/chat/completions' \
--header 'Content-Type: application/json' \
--data ' {
"model": "fake-openai-endpoint",
"messages": [
{
"role": "user",
"content": "Hello, Claude gm!"
}
],
}
'
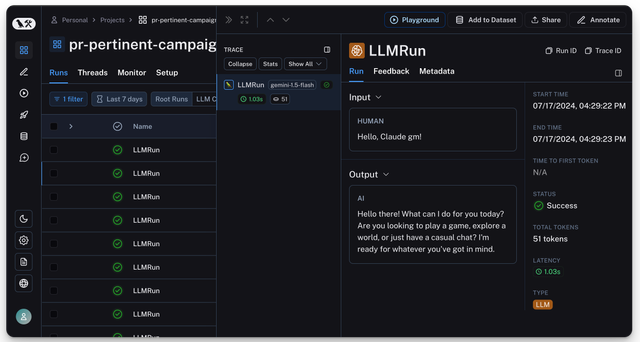
期望在 Langfuse 上看到您的日志
Arize AI
- 在 LiteLLM config.yaml 中设置
success_callback: ["arize"]
model_list:
- model_name: gpt-4
litellm_params:
model: openai/fake
api_key: fake-key
api_base: https://exampleopenaiendpoint-production.up.railway.app/
litellm_settings:
callbacks: ["arize"]
environment_variables:
ARIZE_SPACE_KEY: "d0*****"
ARIZE_API_KEY: "141a****"
ARIZE_ENDPOINT: "https://otlp.arize.com/v1" # OPTIONAL - your custom arize GRPC api endpoint
ARIZE_HTTP_ENDPOINT: "https://otlp.arize.com/v1" # OPTIONAL - your custom arize HTTP api endpoint. Set either this or ARIZE_ENDPOINT
- 启动代理
litellm --config /path/to/config.yaml
- 测试一下!
curl --location 'http://0.0.0.0:4000/chat/completions' \
--header 'Content-Type: application/json' \
--data ' {
"model": "fake-openai-endpoint",
"messages": [
{
"role": "user",
"content": "Hello, Claude gm!"
}
],
}
'
期望在 Langfuse 上看到您的日志
Langtrace
- 在 LiteLLM config.yaml 中设置
success_callback: ["langtrace"]
model_list:
- model_name: gpt-4
litellm_params:
model: openai/fake
api_key: fake-key
api_base: https://exampleopenaiendpoint-production.up.railway.app/
litellm_settings:
callbacks: ["langtrace"]
environment_variables:
LANGTRACE_API_KEY: "141a****"
- 启动代理
litellm --config /path/to/config.yaml
- 测试一下!
curl --location 'http://0.0.0.0:4000/chat/completions' \
--header 'Content-Type: application/json' \
--data ' {
"model": "fake-openai-endpoint",
"messages": [
{
"role": "user",
"content": "Hello, Claude gm!"
}
],
}
'
Galileo
[BETA]
在 www.rungalileo.io 上记录 LLM 输入/输出
Beta 集成
所需环境变量
export GALILEO_BASE_URL="" # For most users, this is the same as their console URL except with the word 'console' replaced by 'api' (e.g. http://www.console.galileo.myenterprise.com -> http://www.api.galileo.myenterprise.com)
export GALILEO_PROJECT_ID=""
export GALILEO_USERNAME=""
export GALILEO_PASSWORD=""
快速入门
- 添加到 Config.yaml
model_list:
- litellm_params:
api_base: https://exampleopenaiendpoint-production.up.railway.app/
api_key: my-fake-key
model: openai/my-fake-model
model_name: fake-openai-endpoint
litellm_settings:
success_callback: ["galileo"] # 👈 KEY CHANGE
- 启动代理
litellm --config /path/to/config.yaml
- 测试一下!
curl --location 'http://0.0.0.0:4000/chat/completions' \
--header 'Content-Type: application/json' \
--data ' {
"model": "fake-openai-endpoint",
"messages": [
{
"role": "user",
"content": "what llm are you"
}
],
}
'
🎉 就是这样 - 期望在您的 Galileo Dashboard 上看到您的日志
OpenMeter
根据客户的 LLM API 使用量使用 OpenMeter 进行计费
所需环境变量
# from https://openmeter.cloud
export OPENMETER_API_ENDPOINT="" # defaults to https://openmeter.cloud
export OPENMETER_API_KEY=""
快速入门
- 添加到 Config.yaml
model_list:
- litellm_params:
api_base: https://openai-function-calling-workers.tasslexyz.workers.dev/
api_key: my-fake-key
model: openai/my-fake-model
model_name: fake-openai-endpoint
litellm_settings:
success_callback: ["openmeter"] # 👈 KEY CHANGE
- 启动代理
litellm --config /path/to/config.yaml
- 测试一下!
curl --location 'http://0.0.0.0:4000/chat/completions' \
--header 'Content-Type: application/json' \
--data ' {
"model": "fake-openai-endpoint",
"messages": [
{
"role": "user",
"content": "what llm are you"
}
],
}
'
DynamoDB
我们将使用 --config 来设置
litellm.success_callback = ["dynamodb"]litellm.dynamodb_table_name = "your-table-name"
这将把所有成功的 LLM 调用记录到 DynamoDB
步骤 1 在 .env 中设置 AWS 凭据
AWS_ACCESS_KEY_ID = ""
AWS_SECRET_ACCESS_KEY = ""
AWS_REGION_NAME = ""
步骤 2: 创建一个 config.yaml 文件并设置 litellm_settings: success_callback
model_list:
- model_name: gpt-3.5-turbo
litellm_params:
model: gpt-3.5-turbo
litellm_settings:
success_callback: ["dynamodb"]
dynamodb_table_name: your-table-name
步骤 3: 启动代理,发起测试请求
启动代理
litellm --config config.yaml --debug
测试请求
curl --location 'http://0.0.0.0:4000/chat/completions' \
--header 'Content-Type: application/json' \
--data ' {
"model": "Azure OpenAI GPT-4 East",
"messages": [
{
"role": "user",
"content": "what llm are you"
}
]
}'
您的日志应可在 DynamoDB 上找到
记录到 DynamoDB 的数据 /chat/completions
{
"id": {
"S": "chatcmpl-8W15J4480a3fAQ1yQaMgtsKJAicen"
},
"call_type": {
"S": "acompletion"
},
"endTime": {
"S": "2023-12-15 17:25:58.424118"
},
"messages": {
"S": "[{'role': 'user', 'content': 'This is a test'}]"
},
"metadata": {
"S": "{}"
},
"model": {
"S": "gpt-3.5-turbo"
},
"modelParameters": {
"S": "{'temperature': 0.7, 'max_tokens': 100, 'user': 'ishaan-2'}"
},
"response": {
"S": "ModelResponse(id='chatcmpl-8W15J4480a3fAQ1yQaMgtsKJAicen', choices=[Choices(finish_reason='stop', index=0, message=Message(content='Great! What can I assist you with?', role='assistant'))], created=1702641357, model='gpt-3.5-turbo-0613', object='chat.completion', system_fingerprint=None, usage=Usage(completion_tokens=9, prompt_tokens=11, total_tokens=20))"
},
"startTime": {
"S": "2023-12-15 17:25:56.047035"
},
"usage": {
"S": "Usage(completion_tokens=9, prompt_tokens=11, total_tokens=20)"
},
"user": {
"S": "ishaan-2"
}
}
记录到 DynamoDB 的数据 /embeddings
{
"id": {
"S": "4dec8d4d-4817-472d-9fc6-c7a6153eb2ca"
},
"call_type": {
"S": "aembedding"
},
"endTime": {
"S": "2023-12-15 17:25:59.890261"
},
"messages": {
"S": "['hi']"
},
"metadata": {
"S": "{}"
},
"model": {
"S": "text-embedding-ada-002"
},
"modelParameters": {
"S": "{'user': 'ishaan-2'}"
},
"response": {
"S": "EmbeddingResponse(model='text-embedding-ada-002-v2', data=[{'embedding': [-0.03503197431564331, -0.020601635798811913, -0.015375726856291294,
}
}
Sentry
如果 API 调用失败(LLM/数据库),您可以将其记录到 Sentry
步骤 1 安装 Sentry
pip install --upgrade sentry-sdk
步骤 2: 保存您的 Sentry_DSN 并添加 litellm_settings: failure_callback
export SENTRY_DSN="your-sentry-dsn"
model_list:
- model_name: gpt-3.5-turbo
litellm_params:
model: gpt-3.5-turbo
litellm_settings:
# other settings
failure_callback: ["sentry"]
general_settings:
database_url: "my-bad-url" # set a fake url to trigger a sentry exception
步骤 3: 启动代理,发起测试请求
启动代理
litellm --config config.yaml --debug
测试请求
litellm --test
Athina
Athina 允许您记录 LLM 输入/输出,用于监控、分析和可观测性。
我们将使用 --config 设置 litellm.success_callback = ["athina"],这将把所有成功的 LLM 调用记录到 Athina
步骤 1 设置 Athina API 密钥
ATHINA_API_KEY = "your-athina-api-key"
步骤 2: 创建一个 config.yaml 文件并设置 litellm_settings: success_callback
model_list:
- model_name: gpt-3.5-turbo
litellm_params:
model: gpt-3.5-turbo
litellm_settings:
success_callback: ["athina"]
步骤 3: 启动代理,发起测试请求
启动代理
litellm --config config.yaml --debug
测试请求
curl --location 'http://0.0.0.0:4000/chat/completions' \
--header 'Content-Type: application/json' \
--data ' {
"model": "gpt-3.5-turbo",
"messages": [
{
"role": "user",
"content": "which llm are you"
}
]
}'