修改 / 拒绝传入请求
- 在代理上进行 LLM API 调用前修改数据
- 在进行 LLM API 调用前 / 在返回响应前拒绝数据
- 对所有 openai 端点调用强制要求 'user' 参数
查看我们并行请求速率限制器的完整示例
快速开始
- 在您的自定义处理器中添加新的
async_pre_call_hook函数
此函数在进行 litellm 完成调用之前被调用,允许您修改进入 litellm 调用的数据 查看代码
from litellm.integrations.custom_logger import CustomLogger
import litellm
from litellm.proxy.proxy_server import UserAPIKeyAuth, DualCache
from typing import Optional, Literal
# This file includes the custom callbacks for LiteLLM Proxy
# Once defined, these can be passed in proxy_config.yaml
class MyCustomHandler(CustomLogger): # https://docs.litellm.com.cn/docs/observability/custom_callback#callback-class
# Class variables or attributes
def __init__(self):
pass
#### CALL HOOKS - proxy only ####
async def async_pre_call_hook(self, user_api_key_dict: UserAPIKeyAuth, cache: DualCache, data: dict, call_type: Literal[
"completion",
"text_completion",
"embeddings",
"image_generation",
"moderation",
"audio_transcription",
]):
data["model"] = "my-new-model"
return data
async def async_post_call_failure_hook(
self,
request_data: dict,
original_exception: Exception,
user_api_key_dict: UserAPIKeyAuth
):
pass
async def async_post_call_success_hook(
self,
data: dict,
user_api_key_dict: UserAPIKeyAuth,
response,
):
pass
async def async_moderation_hook( # call made in parallel to llm api call
self,
data: dict,
user_api_key_dict: UserAPIKeyAuth,
call_type: Literal["completion", "embeddings", "image_generation", "moderation", "audio_transcription"],
):
pass
async def async_post_call_streaming_hook(
self,
user_api_key_dict: UserAPIKeyAuth,
response: str,
):
pass
aasync def async_post_call_streaming_iterator_hook(
self,
user_api_key_dict: UserAPIKeyAuth,
response: Any,
request_data: dict,
) -> AsyncGenerator[ModelResponseStream, None]:
"""
Passes the entire stream to the guardrail
This is useful for plugins that need to see the entire stream.
"""
async for item in response:
yield item
proxy_handler_instance = MyCustomHandler()
- 将此文件添加到您的代理配置中
model_list:
- model_name: gpt-3.5-turbo
litellm_params:
model: gpt-3.5-turbo
litellm_settings:
callbacks: custom_callbacks.proxy_handler_instance # sets litellm.callbacks = [proxy_handler_instance]
- 启动服务器 + 测试请求
$ litellm /path/to/config.yaml
curl --location 'http://0.0.0.0:4000/chat/completions' \
--data ' {
"model": "gpt-3.5-turbo",
"messages": [
{
"role": "user",
"content": "good morning good sir"
}
],
"user": "ishaan-app",
"temperature": 0.2
}'
[测试版] 新增 async_moderation_hook
与实际的 LLM API 调用并行运行审核检查。
在您的自定义处理器中添加新的 async_moderation_hook 函数
- 这目前仅支持
/chat/completion调用。 - 此函数与实际的 LLM API 调用并行运行。
- 如果您的
async_moderation_hook抛出异常,我们将把该异常返回给用户。
信息
未来我们可能需要更新函数 schema,以支持多个端点(例如,接受 call_type)。在使用此功能时,请记住这一点
查看我们Llama Guard 内容审核钩子的完整示例
from litellm.integrations.custom_logger import CustomLogger
import litellm
from fastapi import HTTPException
# This file includes the custom callbacks for LiteLLM Proxy
# Once defined, these can be passed in proxy_config.yaml
class MyCustomHandler(CustomLogger): # https://docs.litellm.com.cn/docs/observability/custom_callback#callback-class
# Class variables or attributes
def __init__(self):
pass
#### ASYNC ####
async def async_log_pre_api_call(self, model, messages, kwargs):
pass
async def async_log_success_event(self, kwargs, response_obj, start_time, end_time):
pass
async def async_log_failure_event(self, kwargs, response_obj, start_time, end_time):
pass
#### CALL HOOKS - proxy only ####
async def async_pre_call_hook(self, user_api_key_dict: UserAPIKeyAuth, cache: DualCache, data: dict, call_type: Literal["completion", "embeddings"]):
data["model"] = "my-new-model"
return data
async def async_moderation_hook( ### 👈 KEY CHANGE ###
self,
data: dict,
):
messages = data["messages"]
print(messages)
if messages[0]["content"] == "hello world":
raise HTTPException(
status_code=400, detail={"error": "Violated content safety policy"}
)
proxy_handler_instance = MyCustomHandler()
- 将此文件添加到您的代理配置中
model_list:
- model_name: gpt-3.5-turbo
litellm_params:
model: gpt-3.5-turbo
litellm_settings:
callbacks: custom_callbacks.proxy_handler_instance # sets litellm.callbacks = [proxy_handler_instance]
- 启动服务器 + 测试请求
$ litellm /path/to/config.yaml
curl --location 'http://0.0.0.0:4000/chat/completions' \
--data ' {
"model": "gpt-3.5-turbo",
"messages": [
{
"role": "user",
"content": "Hello world"
}
],
}'
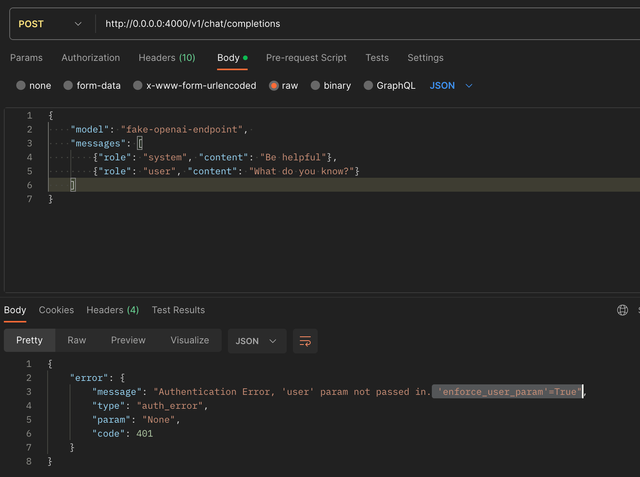
高级 - 强制要求 'user' 参数
将 enforce_user_param 设置为 true,以要求所有对 openai 端点的调用都包含 'user' 参数。
general_settings:
enforce_user_param: True
结果
高级 - 将拒绝的消息作为响应返回
对于聊天完成和文本完成调用,您可以将拒绝的消息作为用户响应返回。
通过返回一个字符串来实现。LiteLLM 会根据端点以及是否为流式/非流式,负责以正确的格式返回响应。
对于非聊天/文本完成端点,此响应将作为 400 状态码异常返回。
1. 创建自定义处理器
from litellm.integrations.custom_logger import CustomLogger
import litellm
from litellm.utils import get_formatted_prompt
# This file includes the custom callbacks for LiteLLM Proxy
# Once defined, these can be passed in proxy_config.yaml
class MyCustomHandler(CustomLogger):
def __init__(self):
pass
#### CALL HOOKS - proxy only ####
async def async_pre_call_hook(self, user_api_key_dict: UserAPIKeyAuth, cache: DualCache, data: dict, call_type: Literal[
"completion",
"text_completion",
"embeddings",
"image_generation",
"moderation",
"audio_transcription",
]) -> Optional[dict, str, Exception]:
formatted_prompt = get_formatted_prompt(data=data, call_type=call_type)
if "Hello world" in formatted_prompt:
return "This is an invalid response"
return data
proxy_handler_instance = MyCustomHandler()
2. 更新 config.yaml
model_list:
- model_name: gpt-3.5-turbo
litellm_params:
model: gpt-3.5-turbo
litellm_settings:
callbacks: custom_callbacks.proxy_handler_instance # sets litellm.callbacks = [proxy_handler_instance]
3. 测试!
$ litellm /path/to/config.yaml
curl --location 'http://0.0.0.0:4000/chat/completions' \
--data ' {
"model": "gpt-3.5-turbo",
"messages": [
{
"role": "user",
"content": "Hello world"
}
],
}'
预期响应
{
"id": "chatcmpl-d00bbede-2d90-4618-bf7b-11a1c23cf360",
"choices": [
{
"finish_reason": "stop",
"index": 0,
"message": {
"content": "This is an invalid response.", # 👈 REJECTED RESPONSE
"role": "assistant"
}
}
],
"created": 1716234198,
"model": null,
"object": "chat.completion",
"system_fingerprint": null,
"usage": {}
}