创建您的第一个 LLM 游乐场
创建一个游乐场,在不到 10 分钟内评估多个 LLM 提供商。如果您想在生产环境中看到这一点,请查看我们的网站。
它会是什么样子?
我们将如何实现?:我们将构建服务器并将其连接到我们的前端模板,最终得到一个可用的游乐场 UI!
信息
在开始之前,请确保您已遵循环境设置指南。请注意,本教程需要您拥有至少一个模型提供商的 API 密钥(例如 OpenAI)。
1. 快速开始
我们来确保密钥正常工作。在您选择的任何环境中运行此脚本(例如 Google Colab)。
🚨 不要忘记用您的密钥替换占位符密钥值!
pip install litellm
from litellm import completion
## set ENV variables
os.environ["OPENAI_API_KEY"] = "openai key" ## REPLACE THIS
os.environ["COHERE_API_KEY"] = "cohere key" ## REPLACE THIS
os.environ["AI21_API_KEY"] = "ai21 key" ## REPLACE THIS
messages = [{ "content": "Hello, how are you?","role": "user"}]
# openai call
response = completion(model="gpt-3.5-turbo", messages=messages)
# cohere call
response = completion("command-nightly", messages)
# ai21 call
response = completion("j2-mid", messages)
2. 设置服务器
我们来构建一个基本的 Flask 应用程序作为后端服务器。我们将为其设置一个专门用于补全调用的路由。
注意:
- 🚨 不要忘记用您的密钥替换占位符密钥值!
completion_with_retries:LLM API 调用在生产环境中可能会失败。此函数使用 tenacity 封装正常的 litellm completion() 调用,以便在失败时重试。
LiteLLM 特定代码片段
import os
from litellm import completion_with_retries
## set ENV variables
os.environ["OPENAI_API_KEY"] = "openai key" ## REPLACE THIS
os.environ["COHERE_API_KEY"] = "cohere key" ## REPLACE THIS
os.environ["AI21_API_KEY"] = "ai21 key" ## REPLACE THIS
@app.route('/chat/completions', methods=["POST"])
def api_completion():
data = request.json
data["max_tokens"] = 256 # By default let's set max_tokens to 256
try:
# COMPLETION CALL
response = completion_with_retries(**data)
except Exception as e:
# print the error
print(e)
return response
完整代码
import os
from flask import Flask, jsonify, request
from litellm import completion_with_retries
## set ENV variables
os.environ["OPENAI_API_KEY"] = "openai key" ## REPLACE THIS
os.environ["COHERE_API_KEY"] = "cohere key" ## REPLACE THIS
os.environ["AI21_API_KEY"] = "ai21 key" ## REPLACE THIS
app = Flask(__name__)
# Example route
@app.route('/', methods=['GET'])
def hello():
return jsonify(message="Hello, Flask!")
@app.route('/chat/completions', methods=["POST"])
def api_completion():
data = request.json
data["max_tokens"] = 256 # By default let's set max_tokens to 256
try:
# COMPLETION CALL
response = completion_with_retries(**data)
except Exception as e:
# print the error
print(e)
return response
if __name__ == '__main__':
from waitress import serve
serve(app, host="0.0.0.0", port=4000, threads=500)
我们来测试一下
启动服务器
python main.py
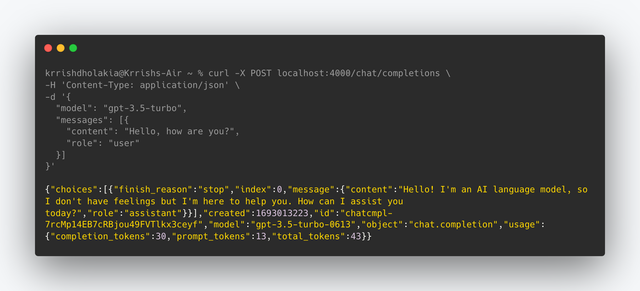
运行此 curl 命令进行测试
curl -X POST localhost:4000/chat/completions \
-H 'Content-Type: application/json' \
-d '{
"model": "gpt-3.5-turbo",
"messages": [{
"content": "Hello, how are you?",
"role": "user"
}]
}'
您应该会看到以下内容
3. 连接到我们的前端模板
3.1 下载模板
对于前端,我们将使用 Streamlit - 它使我们能够构建一个简单的 Python Web 应用程序。
让我们下载我们(LiteLLM)创建的游乐场模板
git clone https://github.com/BerriAI/litellm_playground_fe_template.git
3.2 运行它
确保我们在步骤 2 中的服务器仍在端口 4000 上运行
信息
如果您使用了另一个端口,没关系 - 只需确保更改游乐场模板 app.py 中的此行即可
现在我们来运行应用程序
cd litellm_playground_fe_template && streamlit run app.py
如果您缺少 Streamlit - 只需使用 pip 安装它(或查看他们的安装指南)
pip install streamlit
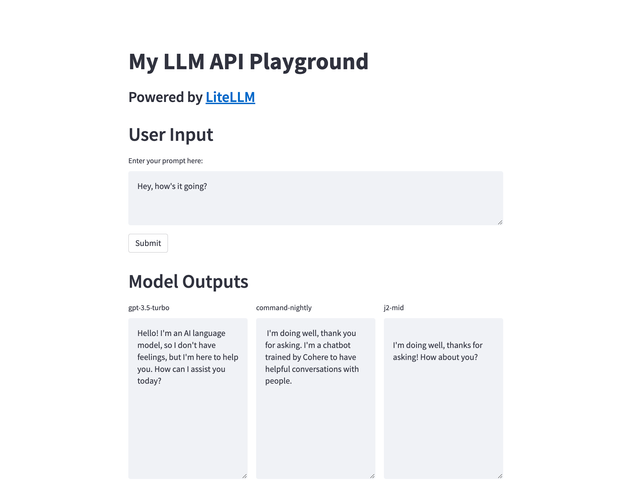
您应该会看到以下内容
恭喜 🚀
您已经创建了您的第一个 LLM 游乐场 - 能够调用 50 多个 LLM API。
后续步骤