会话日志
将请求分组到会话中。这允许您将相关的请求分组在一起。
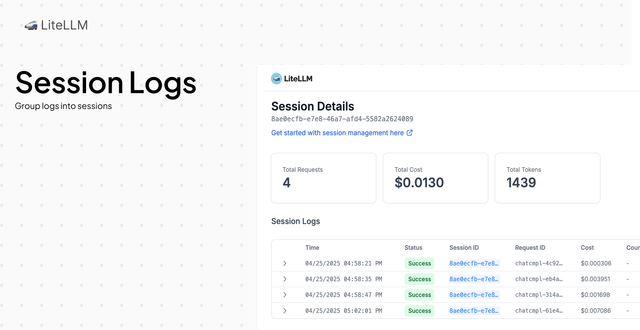
用法
/chat/completions
要将多个请求分组到一个会话中,请在每个请求的元数据中传递相同的 litellm_session_id。以下是如何操作:
- OpenAI Python v1.0.0+
- Langchain
- Curl
- LiteLLM Python SDK
请求 1 创建一个具有唯一 ID 的新会话并发起第一个请求。该会话 ID 将用于跟踪所有相关请求。
import openai
import uuid
# Create a session ID
session_id = str(uuid.uuid4())
client = openai.OpenAI(
api_key="<your litellm api key>",
base_url="http://0.0.0.0:4000"
)
# First request in session
response1 = client.chat.completions.create(
model="gpt-4o",
messages=[
{
"role": "user",
"content": "Write a short story about a robot"
}
],
extra_body={
"metadata": {
"litellm_session_id": session_id # Pass the session ID
}
}
)
请求 2 使用相同的会话 ID 发起另一个请求,将其与先前的请求关联。这允许将相关的请求一起跟踪。
# Second request using same session ID
response2 = client.chat.completions.create(
model="gpt-4o",
messages=[
{
"role": "user",
"content": "Now write a poem about that robot"
}
],
extra_body={
"metadata": {
"litellm_session_id": session_id # Reuse the same session ID
}
}
)
请求 1 使用唯一 ID 初始化新会话,并创建一个聊天模型实例用于发起请求。会话 ID 被嵌入到模型的配置中。
from langchain.chat_models import ChatOpenAI
import uuid
# Create a session ID
session_id = str(uuid.uuid4())
chat = ChatOpenAI(
openai_api_base="http://0.0.0.0:4000",
api_key="<your litellm api key>",
model="gpt-4o",
extra_body={
"metadata": {
"litellm_session_id": session_id # Pass the session ID
}
}
)
# First request in session
response1 = chat.invoke("Write a short story about a robot")
请求 2 使用相同的聊天模型实例发起另一个请求,通过之前配置的会话 ID 自动维护会话上下文。
# Second request using same chat object and session ID
response2 = chat.invoke("Now write a poem about that robot")
请求 1 生成一个新的会话 ID 并进行初始 API 调用。元数据中的会话 ID 将用于跟踪此对话。
# Create a session ID
SESSION_ID=$(uuidgen)
# Store your API key
API_KEY="<your litellm api key>"
# First request in session
curl --location 'http://0.0.0.0:4000/chat/completions' \
--header 'Content-Type: application/json' \
--header "Authorization: Bearer $API_KEY" \
--data '{
"model": "gpt-4o",
"messages": [
{
"role": "user",
"content": "Write a short story about a robot"
}
],
"metadata": {
"litellm_session_id": "'$SESSION_ID'"
}
}'
请求 2 使用相同的会话 ID 进行后续请求,以维护对话上下文和跟踪。
# Second request using same session ID
curl --location 'http://0.0.0.0:4000/chat/completions' \
--header 'Content-Type: application/json' \
--header "Authorization: Bearer $API_KEY" \
--data '{
"model": "gpt-4o",
"messages": [
{
"role": "user",
"content": "Now write a poem about that robot"
}
],
"metadata": {
"litellm_session_id": "'$SESSION_ID'"
}
}'
请求 1 通过创建一个唯一 ID 并发起初始请求来启动新会话。此会话 ID 将用于将相关的请求分组在一起。
import litellm
import uuid
# Create a session ID
session_id = str(uuid.uuid4())
# First request in session
response1 = litellm.completion(
model="gpt-4o",
messages=[{"role": "user", "content": "Write a short story about a robot"}],
api_base="http://0.0.0.0:4000",
api_key="<your litellm api key>",
metadata={
"litellm_session_id": session_id # Pass the session ID
}
)
请求 2 使用相同的会话 ID 发起另一个请求以继续对话,将其与之前的交互关联。
# Second request using same session ID
response2 = litellm.completion(
model="gpt-4o",
messages=[{"role": "user", "content": "Now write a poem about that robot"}],
api_base="http://0.0.0.0:4000",
api_key="<your litellm api key>",
metadata={
"litellm_session_id": session_id # Reuse the same session ID
}
)
/responses
对于 /responses 端点,使用 previous_response_id 将请求分组到会话中。previous_response_id 在每个请求的响应中返回。
- OpenAI Python v1.0.0+
- Curl
- LiteLLM Python SDK
请求 1 发起初始请求并存储响应 ID,用于链接后续请求。
from openai import OpenAI
client = OpenAI(
api_key="<your litellm api key>",
base_url="http://0.0.0.0:4000"
)
# First request in session
response1 = client.responses.create(
model="anthropic/claude-3-sonnet-20240229-v1:0",
input="Write a short story about a robot"
)
# Store the response ID for the next request
response_id = response1.id
请求 2 使用上一个响应 ID 发起后续请求,以维护对话上下文。
# Second request using previous response ID
response2 = client.responses.create(
model="anthropic/claude-3-sonnet-20240229-v1:0",
input="Now write a poem about that robot",
previous_response_id=response_id # Link to previous request
)
请求 1 发起初始请求。响应将包含一个可用于链接后续请求的 ID。
# Store your API key
API_KEY="<your litellm api key>"
# First request in session
curl https://:4000/v1/responses \
--header 'Content-Type: application/json' \
--header "Authorization: Bearer $API_KEY" \
--data '{
"model": "anthropic/claude-3-sonnet-20240229-v1:0",
"input": "Write a short story about a robot"
}'
# Response will include an 'id' field that you'll use in the next request
请求 2 使用上一个响应 ID 发起后续请求,以维护对话上下文。
# Second request using previous response ID
curl https://:4000/v1/responses \
--header 'Content-Type: application/json' \
--header "Authorization: Bearer $API_KEY" \
--data '{
"model": "anthropic/claude-3-sonnet-20240229-v1:0",
"input": "Now write a poem about that robot",
"previous_response_id": "resp_abc123..." # Replace with actual response ID from previous request
}'
请求 1 发起初始请求并存储响应 ID,用于链接后续请求。
import litellm
# First request in session
response1 = litellm.responses(
model="anthropic/claude-3-sonnet-20240229-v1:0",
input="Write a short story about a robot",
api_base="http://0.0.0.0:4000",
api_key="<your litellm api key>"
)
# Store the response ID for the next request
response_id = response1.id
请求 2 使用上一个响应 ID 发起后续请求,以维护对话上下文。
# Second request using previous response ID
response2 = litellm.responses(
model="anthropic/claude-3-sonnet-20240229-v1:0",
input="Now write a poem about that robot",
api_base="http://0.0.0.0:4000",
api_key="<your litellm api key>",
previous_response_id=response_id # Link to previous request
)