

部署此版本
- Docker
- Pip
docker run litellm
docker run
-e STORE_MODEL_IN_DB=True
-p 4000:4000
ghcr.io/berriai/litellm:main-v1.68.0-stable
pip install litellm
pip install litellm==1.68.0.post1
主要亮点
LiteLLM v1.68.0-stable 即将上线。以下是本次版本的主要亮点
- Bedrock 知识库:您现在可以通过
/chat/completion或/responsesAPI 使用所有 LiteLLM 模型查询您的 Bedrock 知识库。 - 速率限制:此版本在多个实例之间提供了精确的速率限制,在高流量下,将溢出请求最多减少到 10 个额外请求。
- Meta Llama API:增加了对 Meta Llama API 的支持 开始使用
- LlamaFile:增加了对 LlamaFile 的支持 开始使用
Bedrock 知识库(向量存储)
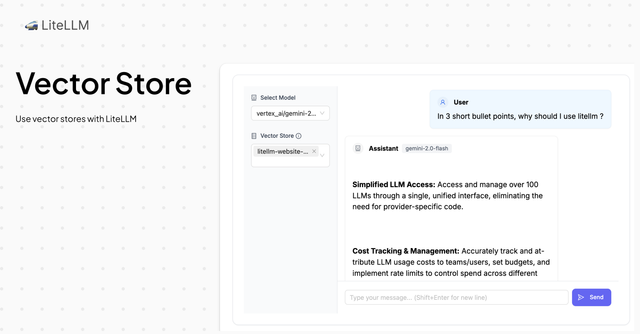
此版本在 LiteLLM 中添加了对 Bedrock 向量存储(知识库)的支持。通过此更新,您可以
- 在 OpenAI /chat/completions 规范中使用 Bedrock 向量存储,支持所有 LiteLLM 支持的模型。
- 通过 LiteLLM UI 或 API 查看所有可用的向量存储。
- 配置向量存储以使其始终对特定模型处于活动状态。
- 在 LiteLLM 日志中跟踪向量存储使用情况。
对于下一个版本,我们计划允许您为向量存储设置 key、用户、团队、组织权限。
速率限制
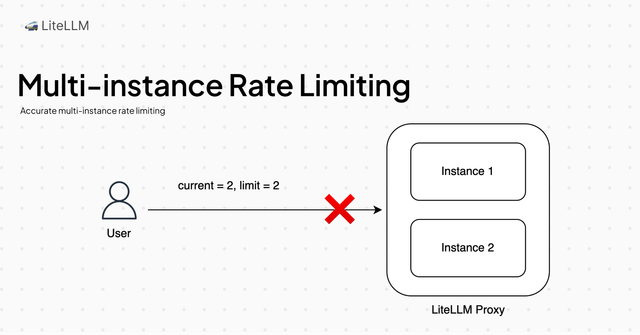
此版本带来了跨 key/用户/团队的精确多实例速率限制。以下概述了关键工程变更
- 变更:实例现在是递增缓存值而不是设置它。为了避免在每个请求时调用 Redis,此操作每 0.01 秒同步一次。
- 准确性:在测试中,我们看到在高流量下(100 RPS,3 个实例),最大溢出请求从预期的 10 个,降至当前的 189 个溢出请求
- 性能:我们的负载测试显示,在高流量下,这将使中位数响应时间减少 100 毫秒
这目前处于功能标志后面,我们计划下周将其作为默认设置。要立即启用此功能,只需添加此环境变量
export LITELLM_RATE_LIMIT_ACCURACY=true
新模型/更新模型
- Gemini (VertexAI + Google AI Studio)
- VertexAI
- Bedrock
- OpenAI
- 🆕 Meta Llama API 提供者 PR
- 🆕 LlamaFile 提供者 PR
LLM API 端点
- 响应 API
- 处理多轮会话的修复 PR
- 嵌入
- 缓存修复 - PR
- 处理 str -> 列表缓存
- 缓存命中时返回使用令牌
- 部分缓存命中时合并使用令牌
- 缓存修复 - PR
- 🆕 向量存储
- MCP
- 审核
- 为
/moderationsAPI 添加日志回调支持 - PR
- 为
支出跟踪/预算改进
- OpenAI
- computer-use-preview 成本跟踪/定价 PR
- gpt-4o-mini-tts 输入成本跟踪 - PR
- Fireworks AI - 定价更新 - 新的
0-4b模型定价层级 + llama4 模型定价 - 预算
- 令牌计数
- 重写 token_counter() 函数以防止令牌计数不足 - PR
管理端点/UI
日志记录/安全防护集成
- Langsmith
- 遵守 langsmith_batch_size 参数 - PR
性能/负载均衡/可靠性改进
- Redis
- 确保所有 redis 队列定期刷新,这解决了使用请求标签时 redis 队列大小无限增长的问题 - PR
- 速率限制
- Azure OpenAI OIDC
通用代理改进
- 安全性
- 认证
- 默认支持
x-litellm-api-key请求头参数,这解决了之前版本中x-litellm-api-key未在 vertex ai 直通请求中使用的问题 - PR - 允许达到最大预算的密钥调用非 llm api 端点 - PR
- 默认支持
- 🆕 用于 LiteLLM Proxy 管理端点的Python 客户端库
- 依赖项
- Windows 不再需要 uvloop - PR