VertexAI[Anthropic, Gemini, Model Garden]
概述
| 属性 | 详情 |
|---|---|
| 描述 | Vertex AI 是一个用于构建和使用生成式 AI 的全托管 AI 开发平台。 |
| LiteLLM 上的提供商路由 | vertex_ai/ |
| 提供商文档链接 | Vertex AI ↗ |
| Base URL | https://{vertex_location}-aiplatform.googleapis.com/ |
| 支持的操作 | /chat/completions, /completions, /embeddings, /audio/speech, /fine_tuning, /batches, /files, /images |
vertex_ai/ 路由
vertex_ai/ 路由使用 VertexAI 的 REST API。
from litellm import completion
import json
## GET CREDENTIALS
## RUN ##
# !gcloud auth application-default login - run this to add vertex credentials to your env
## OR ##
file_path = 'path/to/vertex_ai_service_account.json'
# Load the JSON file
with open(file_path, 'r') as file:
vertex_credentials = json.load(file)
# Convert to JSON string
vertex_credentials_json = json.dumps(vertex_credentials)
## COMPLETION CALL
response = completion(
model="vertex_ai/gemini-pro",
messages=[{ "content": "Hello, how are you?","role": "user"}],
vertex_credentials=vertex_credentials_json
)
系统消息
from litellm import completion
import json
## GET CREDENTIALS
file_path = 'path/to/vertex_ai_service_account.json'
# Load the JSON file
with open(file_path, 'r') as file:
vertex_credentials = json.load(file)
# Convert to JSON string
vertex_credentials_json = json.dumps(vertex_credentials)
response = completion(
model="vertex_ai/gemini-pro",
messages=[{"content": "You are a good bot.","role": "system"}, {"content": "Hello, how are you?","role": "user"}],
vertex_credentials=vertex_credentials_json
)
函数调用
使用 tool_choice="required" 强制 Gemini 进行工具调用。
from litellm import completion
import json
## GET CREDENTIALS
file_path = 'path/to/vertex_ai_service_account.json'
# Load the JSON file
with open(file_path, 'r') as file:
vertex_credentials = json.load(file)
# Convert to JSON string
vertex_credentials_json = json.dumps(vertex_credentials)
messages = [
{
"role": "system",
"content": "Your name is Litellm Bot, you are a helpful assistant",
},
# User asks for their name and weather in San Francisco
{
"role": "user",
"content": "Hello, what is your name and can you tell me the weather?",
},
]
tools = [
{
"type": "function",
"function": {
"name": "get_weather",
"description": "Get the current weather in a given location",
"parameters": {
"type": "object",
"properties": {
"location": {
"type": "string",
"description": "The city and state, e.g. San Francisco, CA",
}
},
"required": ["location"],
},
},
}
]
data = {
"model": "vertex_ai/gemini-1.5-pro-preview-0514"),
"messages": messages,
"tools": tools,
"tool_choice": "required",
"vertex_credentials": vertex_credentials_json
}
## COMPLETION CALL
print(completion(**data))
JSON Schema
从 v1.40.1+ 开始,LiteLLM 支持将 response_schema 作为参数发送给 Vertex AI 上的 Gemini-1.5-Pro。对于其他模型(例如 gemini-1.5-flash 或 claude-3-5-sonnet),LiteLLM 会将 schema 添加到消息列表中,并带有用户控制的 prompt。
响应 Schema
- SDK
- 代理
from litellm import completion
import json
## SETUP ENVIRONMENT
# !gcloud auth application-default login - run this to add vertex credentials to your env
messages = [
{
"role": "user",
"content": "List 5 popular cookie recipes."
}
]
response_schema = {
"type": "array",
"items": {
"type": "object",
"properties": {
"recipe_name": {
"type": "string",
},
},
"required": ["recipe_name"],
},
}
completion(
model="vertex_ai/gemini-1.5-pro",
messages=messages,
response_format={"type": "json_object", "response_schema": response_schema} # 👈 KEY CHANGE
)
print(json.loads(completion.choices[0].message.content))
- 将模型添加到 config.yaml
model_list:
- model_name: gemini-pro
litellm_params:
model: vertex_ai/gemini-1.5-pro
vertex_project: "project-id"
vertex_location: "us-central1"
vertex_credentials: "/path/to/service_account.json" # [OPTIONAL] Do this OR `!gcloud auth application-default login` - run this to add vertex credentials to your env
- 启动代理
$ litellm --config /path/to/config.yaml
- 发送请求!
curl -X POST 'http://0.0.0.0:4000/chat/completions' \
-H 'Content-Type: application/json' \
-H 'Authorization: Bearer sk-1234' \
-D '{
"model": "gemini-pro",
"messages": [
{"role": "user", "content": "List 5 popular cookie recipes."}
],
"response_format": {"type": "json_object", "response_schema": {
"type": "array",
"items": {
"type": "object",
"properties": {
"recipe_name": {
"type": "string",
},
},
"required": ["recipe_name"],
},
}}
}
'
验证 Schema
要验证 response_schema,请设置 enforce_validation: true。
- SDK
- 代理
from litellm import completion, JSONSchemaValidationError
try:
completion(
model="vertex_ai/gemini-1.5-pro",
messages=messages,
response_format={
"type": "json_object",
"response_schema": response_schema,
"enforce_validation": true # 👈 KEY CHANGE
}
)
except JSONSchemaValidationError as e:
print("Raw Response: {}".format(e.raw_response))
raise e
- 将模型添加到 config.yaml
model_list:
- model_name: gemini-pro
litellm_params:
model: vertex_ai/gemini-1.5-pro
vertex_project: "project-id"
vertex_location: "us-central1"
vertex_credentials: "/path/to/service_account.json" # [OPTIONAL] Do this OR `!gcloud auth application-default login` - run this to add vertex credentials to your env
- 启动代理
$ litellm --config /path/to/config.yaml
- 发送请求!
curl -X POST 'http://0.0.0.0:4000/chat/completions' \
-H 'Content-Type: application/json' \
-H 'Authorization: Bearer sk-1234' \
-D '{
"model": "gemini-pro",
"messages": [
{"role": "user", "content": "List 5 popular cookie recipes."}
],
"response_format": {"type": "json_object", "response_schema": {
"type": "array",
"items": {
"type": "object",
"properties": {
"recipe_name": {
"type": "string",
},
},
"required": ["recipe_name"],
},
},
"enforce_validation": true
}
}
'
LiteLLM 将根据 schema 验证响应,如果响应与 schema 不匹配,则会引发 JSONSchemaValidationError。
JSONSchemaValidationError 继承自 openai.APIError
使用 e.raw_response 访问原始响应
自己添加到 prompt
from litellm import completion
## GET CREDENTIALS
file_path = 'path/to/vertex_ai_service_account.json'
# Load the JSON file
with open(file_path, 'r') as file:
vertex_credentials = json.load(file)
# Convert to JSON string
vertex_credentials_json = json.dumps(vertex_credentials)
messages = [
{
"role": "user",
"content": """
List 5 popular cookie recipes.
Using this JSON schema:
Recipe = {"recipe_name": str}
Return a `list[Recipe]`
"""
}
]
completion(model="vertex_ai/gemini-1.5-flash-preview-0514", messages=messages, response_format={ "type": "json_object" })
基础(Grounding)- 网页搜索
将 Google 搜索结果 grounding 添加到 Vertex AI 调用。
使用 response_obj._hidden_params["vertex_ai_grounding_metadata"] 查看 grounding 元数据
- SDK
- 代理
from litellm import completion
## SETUP ENVIRONMENT
# !gcloud auth application-default login - run this to add vertex credentials to your env
tools = [{"googleSearch": {}}] # 👈 ADD GOOGLE SEARCH
resp = litellm.completion(
model="vertex_ai/gemini-1.0-pro-001",
messages=[{"role": "user", "content": "Who won the world cup?"}],
tools=tools,
)
print(resp)
- OpenAI Python SDK
- cURL
from openai import OpenAI
client = OpenAI(
api_key="sk-1234", # pass litellm proxy key, if you're using virtual keys
base_url="http://0.0.0.0:4000/v1/" # point to litellm proxy
)
response = client.chat.completions.create(
model="gemini-pro",
messages=[{"role": "user", "content": "Who won the world cup?"}],
tools=[{"googleSearch": {}}],
)
print(response)
curl https://:4000/v1/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer sk-1234" \
-d '{
"model": "gemini-pro",
"messages": [
{"role": "user", "content": "Who won the world cup?"}
],
"tools": [
{
"googleSearch": {}
}
]
}'
您还可以使用 enterpriseWebSearch 工具进行企业合规搜索。
- SDK
- 代理
from litellm import completion
## SETUP ENVIRONMENT
# !gcloud auth application-default login - run this to add vertex credentials to your env
tools = [{"enterpriseWebSearch": {}}] # 👈 ADD GOOGLE ENTERPRISE SEARCH
resp = litellm.completion(
model="vertex_ai/gemini-1.0-pro-001",
messages=[{"role": "user", "content": "Who won the world cup?"}],
tools=tools,
)
print(resp)
- OpenAI Python SDK
- cURL
from openai import OpenAI
client = OpenAI(
api_key="sk-1234", # pass litellm proxy key, if you're using virtual keys
base_url="http://0.0.0.0:4000/v1/" # point to litellm proxy
)
response = client.chat.completions.create(
model="gemini-pro",
messages=[{"role": "user", "content": "Who won the world cup?"}],
tools=[{"enterpriseWebSearch": {}}],
)
print(response)
curl https://:4000/v1/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer sk-1234" \
-d '{
"model": "gemini-pro",
"messages": [
{"role": "user", "content": "Who won the world cup?"}
],
"tools": [
{
"enterpriseWebSearch": {}
}
]
}'
从 Vertex AI SDK 迁移到 LiteLLM (GROUNDING)
如果这是您最初的 VertexAI Grounding 代码,
import vertexai
from vertexai.generative_models import GenerativeModel, GenerationConfig, Tool, grounding
vertexai.init(project=project_id, location="us-central1")
model = GenerativeModel("gemini-1.5-flash-001")
# Use Google Search for grounding
tool = Tool.from_google_search_retrieval(grounding.GoogleSearchRetrieval())
prompt = "When is the next total solar eclipse in US?"
response = model.generate_content(
prompt,
tools=[tool],
generation_config=GenerationConfig(
temperature=0.0,
),
)
print(response)
那么,现在看起来是这样
from litellm import completion
# !gcloud auth application-default login - run this to add vertex credentials to your env
tools = [{"googleSearch": {"disable_attributon": False}}] # 👈 ADD GOOGLE SEARCH
resp = litellm.completion(
model="vertex_ai/gemini-1.0-pro-001",
messages=[{"role": "user", "content": "Who won the world cup?"}],
tools=tools,
vertex_project="project-id"
)
print(resp)
思考 / reasoning_content
LiteLLM 将 OpenAI 的 reasoning_effort 转换为 Gemini 的 thinking 参数。代码
映射
| reasoning_effort | thinking |
|---|---|
| "低" | "budget_tokens": 1024 |
| "中" | "budget_tokens": 2048 |
| "高" | "budget_tokens": 4096 |
- SDK
- 代理
from litellm import completion
# !gcloud auth application-default login - run this to add vertex credentials to your env
resp = completion(
model="vertex_ai/gemini-2.5-flash-preview-04-17",
messages=[{"role": "user", "content": "What is the capital of France?"}],
reasoning_effort="low",
vertex_project="project-id",
vertex_location="us-central1"
)
- 设置 config.yaml
- model_name: gemini-2.5-flash
litellm_params:
model: vertex_ai/gemini-2.5-flash-preview-04-17
vertex_credentials: {"project_id": "project-id", "location": "us-central1", "project_key": "project-key"}
vertex_project: "project-id"
vertex_location: "us-central1"
- 启动代理
litellm --config /path/to/config.yaml
- 测试一下!
curl http://0.0.0.0:4000/v1/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer <YOUR-LITELLM-KEY>" \
-d '{
"model": "gemini-2.5-flash",
"messages": [{"role": "user", "content": "What is the capital of France?"}],
"reasoning_effort": "low"
}'
预期响应
ModelResponse(
id='chatcmpl-c542d76d-f675-4e87-8e5f-05855f5d0f5e',
created=1740470510,
model='claude-3-7-sonnet-20250219',
object='chat.completion',
system_fingerprint=None,
choices=[
Choices(
finish_reason='stop',
index=0,
message=Message(
content="The capital of France is Paris.",
role='assistant',
tool_calls=None,
function_call=None,
reasoning_content='The capital of France is Paris. This is a very straightforward factual question.'
),
)
],
usage=Usage(
completion_tokens=68,
prompt_tokens=42,
total_tokens=110,
completion_tokens_details=None,
prompt_tokens_details=PromptTokensDetailsWrapper(
audio_tokens=None,
cached_tokens=0,
text_tokens=None,
image_tokens=None
),
cache_creation_input_tokens=0,
cache_read_input_tokens=0
)
)
将 thinking 参数传递给 Gemini 模型
您也可以将 thinking 参数传递给 Gemini 模型。
这被转换为 Gemini 的thinkingConfig 参数。
- SDK
- 代理
from litellm import completion
# !gcloud auth application-default login - run this to add vertex credentials to your env
response = litellm.completion(
model="vertex_ai/gemini-2.5-flash-preview-04-17",
messages=[{"role": "user", "content": "What is the capital of France?"}],
thinking={"type": "enabled", "budget_tokens": 1024},
vertex_project="project-id",
vertex_location="us-central1"
)
curl http://0.0.0.0:4000/v1/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer $LITELLM_KEY" \
-d '{
"model": "vertex_ai/gemini-2.5-flash-preview-04-17",
"messages": [{"role": "user", "content": "What is the capital of France?"}],
"thinking": {"type": "enabled", "budget_tokens": 1024}
}'
上下文缓存
通过直接调用提供商 API 支持 Vertex AI 上下文缓存。(统一端点支持即将推出。)
先决条件
pip install google-cloud-aiplatform(已预装在代理 docker 镜像中)身份验证
运行
gcloud auth application-default login。请参阅Google Cloud 文档或者,您可以设置
GOOGLE_APPLICATION_CREDENTIALS方法如下:跳到代码
- 在 GCP 上创建一个服务帐号
- 将凭据导出为 json
- 加载 json 并将 json.dump 的结果作为字符串
- 将 json 字符串存储在您的环境变量
GOOGLE_APPLICATION_CREDENTIALS中
示例用法
import litellm
litellm.vertex_project = "hardy-device-38811" # Your Project ID
litellm.vertex_location = "us-central1" # proj location
response = litellm.completion(model="gemini-pro", messages=[{"role": "user", "content": "write code for saying hi from LiteLLM"}])
LiteLLM 代理服务器用法
以下是如何将 Vertex AI 与 LiteLLM 代理服务器一起使用的方法
修改 config.yaml
- 每个模型的不同位置
- 一个位置用于所有 Vertex 模型
当您需要为每个 Vertex 模型设置不同位置时使用此选项
model_list:
- model_name: gemini-vision
litellm_params:
model: vertex_ai/gemini-1.0-pro-vision-001
vertex_project: "project-id"
vertex_location: "us-central1"
- model_name: gemini-vision
litellm_params:
model: vertex_ai/gemini-1.0-pro-vision-001
vertex_project: "project-id2"
vertex_location: "us-east"当您有一个 Vertex 位置用于所有模型时使用此选项
litellm_settings:
vertex_project: "hardy-device-38811" # Your Project ID
vertex_location: "us-central1" # proj location
model_list:
-model_name: team1-gemini-pro
litellm_params:
model: gemini-pro启动代理
$ litellm --config /path/to/config.yaml发送请求到 LiteLLM 代理服务器
- OpenAI Python v1.0.0+
- curl
import openai
client = openai.OpenAI(
api_key="sk-1234", # pass litellm proxy key, if you're using virtual keys
base_url="http://0.0.0.0:4000" # litellm-proxy-base url
)
response = client.chat.completions.create(
model="team1-gemini-pro",
messages = [
{
"role": "user",
"content": "what llm are you"
}
],
)
print(response)curl --location 'http://0.0.0.0:4000/chat/completions' \
--header 'Authorization: Bearer sk-1234' \
--header 'Content-Type: application/json' \
--data '{
"model": "team1-gemini-pro",
"messages": [
{
"role": "user",
"content": "what llm are you"
}
],
}'
身份验证 - vertex_project, vertex_location 等。
通过以下方式设置您的 Vertex 凭据
- 动态参数 或
- 环境变量
动态参数
您可以设置
vertex_credentials(str) - 可以是 json 字符串或指向您的 vertex ai 服务帐号 .json 文件的路径vertex_location(str) - Vertex 模型部署的位置 (us-central1, asia-southeast1 等)vertex_project(可选)[str]- 如果 Vertex 项目与 vertex_credentials 中的不同,则使用此项
作为 litellm.completion 调用的动态参数。
- SDK
- 代理
from litellm import completion
import json
## GET CREDENTIALS
file_path = 'path/to/vertex_ai_service_account.json'
# Load the JSON file
with open(file_path, 'r') as file:
vertex_credentials = json.load(file)
# Convert to JSON string
vertex_credentials_json = json.dumps(vertex_credentials)
response = completion(
model="vertex_ai/gemini-pro",
messages=[{"content": "You are a good bot.","role": "system"}, {"content": "Hello, how are you?","role": "user"}],
vertex_credentials=vertex_credentials_json,
vertex_project="my-special-project",
vertex_location="my-special-location"
)
model_list:
- model_name: gemini-1.5-pro
litellm_params:
model: gemini-1.5-pro
vertex_credentials: os.environ/VERTEX_FILE_PATH_ENV_VAR # os.environ["VERTEX_FILE_PATH_ENV_VAR"] = "/path/to/service_account.json"
vertex_project: "my-special-project"
vertex_location: "my-special-location:
环境变量
您可以设置
GOOGLE_APPLICATION_CREDENTIALS- 在此处存储您的 service_account.json 文件路径(Vertex SDK 直接使用)。- VERTEXAI_LOCATION - Vertex 模型部署的位置 (us-central1, asia-southeast1 等)
- VERTEXAI_PROJECT - 可选[str]- 如果 Vertex 项目与 vertex_credentials 中的不同,则使用此项
- GOOGLE_APPLICATION_CREDENTIALS
export GOOGLE_APPLICATION_CREDENTIALS="/path/to/service_account.json"
- VERTEXAI_LOCATION
export VERTEXAI_LOCATION="us-central1" # can be any vertex location
- VERTEXAI_PROJECT
export VERTEXAI_PROJECT="my-test-project" # ONLY use if model project is different from service account project
指定安全设置
在某些用例中,您可能需要调用模型并传递与默认设置不同的安全设置。为此,只需将 safety_settings 参数传递给 completion 或 acompletion。例如
按模型/请求设置
- SDK
- 代理
response = completion(
model="vertex_ai/gemini-pro",
messages=[{"role": "user", "content": "write code for saying hi from LiteLLM"}]
safety_settings=[
{
"category": "HARM_CATEGORY_HARASSMENT",
"threshold": "BLOCK_NONE",
},
{
"category": "HARM_CATEGORY_HATE_SPEECH",
"threshold": "BLOCK_NONE",
},
{
"category": "HARM_CATEGORY_SEXUALLY_EXPLICIT",
"threshold": "BLOCK_NONE",
},
{
"category": "HARM_CATEGORY_DANGEROUS_CONTENT",
"threshold": "BLOCK_NONE",
},
]
)
选项 1:在 config 中设置
model_list:
- model_name: gemini-experimental
litellm_params:
model: vertex_ai/gemini-experimental
vertex_project: litellm-epic
vertex_location: us-central1
safety_settings:
- category: HARM_CATEGORY_HARASSMENT
threshold: BLOCK_NONE
- category: HARM_CATEGORY_HATE_SPEECH
threshold: BLOCK_NONE
- category: HARM_CATEGORY_SEXUALLY_EXPLICIT
threshold: BLOCK_NONE
- category: HARM_CATEGORY_DANGEROUS_CONTENT
threshold: BLOCK_NONE
选项 2:在调用时设置
response = client.chat.completions.create(
model="gemini-experimental",
messages=[
{
"role": "user",
"content": "Can you write exploits?",
}
],
max_tokens=8192,
stream=False,
temperature=0.0,
extra_body={
"safety_settings": [
{
"category": "HARM_CATEGORY_HARASSMENT",
"threshold": "BLOCK_NONE",
},
{
"category": "HARM_CATEGORY_HATE_SPEECH",
"threshold": "BLOCK_NONE",
},
{
"category": "HARM_CATEGORY_SEXUALLY_EXPLICIT",
"threshold": "BLOCK_NONE",
},
{
"category": "HARM_CATEGORY_DANGEROUS_CONTENT",
"threshold": "BLOCK_NONE",
},
],
}
)
全局设置
- SDK
- 代理
import litellm
litellm.set_verbose = True 👈 See RAW REQUEST/RESPONSE
litellm.vertex_ai_safety_settings = [
{
"category": "HARM_CATEGORY_HARASSMENT",
"threshold": "BLOCK_NONE",
},
{
"category": "HARM_CATEGORY_HATE_SPEECH",
"threshold": "BLOCK_NONE",
},
{
"category": "HARM_CATEGORY_SEXUALLY_EXPLICIT",
"threshold": "BLOCK_NONE",
},
{
"category": "HARM_CATEGORY_DANGEROUS_CONTENT",
"threshold": "BLOCK_NONE",
},
]
response = completion(
model="vertex_ai/gemini-pro",
messages=[{"role": "user", "content": "write code for saying hi from LiteLLM"}]
)
model_list:
- model_name: gemini-experimental
litellm_params:
model: vertex_ai/gemini-experimental
vertex_project: litellm-epic
vertex_location: us-central1
litellm_settings:
vertex_ai_safety_settings:
- category: HARM_CATEGORY_HARASSMENT
threshold: BLOCK_NONE
- category: HARM_CATEGORY_HATE_SPEECH
threshold: BLOCK_NONE
- category: HARM_CATEGORY_SEXUALLY_EXPLICIT
threshold: BLOCK_NONE
- category: HARM_CATEGORY_DANGEROUS_CONTENT
threshold: BLOCK_NONE
设置 Vertex 项目和 Vertex 位置
所有使用 Vertex AI 的调用都需要以下参数
- 您的项目 ID
import os, litellm
# set via env var
os.environ["VERTEXAI_PROJECT"] = "hardy-device-38811" # Your Project ID`
### OR ###
# set directly on module
litellm.vertex_project = "hardy-device-38811" # Your Project ID`
- 您的项目位置
import os, litellm
# set via env var
os.environ["VERTEXAI_LOCATION"] = "us-central1 # Your Location
### OR ###
# set directly on module
litellm.vertex_location = "us-central1 # Your Location
Anthropic
| 模型名称 | 函数调用 |
|---|---|
| claude-3-opus@20240229 | completion('vertex_ai/claude-3-opus@20240229', messages) |
| claude-3-5-sonnet@20240620 | completion('vertex_ai/claude-3-5-sonnet@20240620', messages) |
| claude-3-sonnet@20240229 | completion('vertex_ai/claude-3-sonnet@20240229', messages) |
| claude-3-haiku@20240307 | completion('vertex_ai/claude-3-haiku@20240307', messages) |
| claude-3-7-sonnet@20250219 | completion('vertex_ai/claude-3-7-sonnet@20250219', messages) |
用法
- SDK
- 代理
from litellm import completion
import os
os.environ["GOOGLE_APPLICATION_CREDENTIALS"] = ""
model = "claude-3-sonnet@20240229"
vertex_ai_project = "your-vertex-project" # can also set this as os.environ["VERTEXAI_PROJECT"]
vertex_ai_location = "your-vertex-location" # can also set this as os.environ["VERTEXAI_LOCATION"]
response = completion(
model="vertex_ai/" + model,
messages=[{"role": "user", "content": "hi"}],
temperature=0.7,
vertex_ai_project=vertex_ai_project,
vertex_ai_location=vertex_ai_location,
)
print("\nModel Response", response)
1. 添加到 config
model_list:
- model_name: anthropic-vertex
litellm_params:
model: vertex_ai/claude-3-sonnet@20240229
vertex_ai_project: "my-test-project"
vertex_ai_location: "us-east-1"
- model_name: anthropic-vertex
litellm_params:
model: vertex_ai/claude-3-sonnet@20240229
vertex_ai_project: "my-test-project"
vertex_ai_location: "us-west-1"
2. 启动代理
litellm --config /path/to/config.yaml
# RUNNING at http://0.0.0.0:4000
3. 测试一下!
curl --location 'http://0.0.0.0:4000/chat/completions' \
--header 'Authorization: Bearer sk-1234' \
--header 'Content-Type: application/json' \
--data '{
"model": "anthropic-vertex", # 👈 the 'model_name' in config
"messages": [
{
"role": "user",
"content": "what llm are you"
}
],
}'
用法 - thinking / reasoning_content
- SDK
- 代理
from litellm import completion
resp = completion(
model="vertex_ai/claude-3-7-sonnet-20250219",
messages=[{"role": "user", "content": "What is the capital of France?"}],
thinking={"type": "enabled", "budget_tokens": 1024},
)
- 设置 config.yaml
- model_name: claude-3-7-sonnet-20250219
litellm_params:
model: vertex_ai/claude-3-7-sonnet-20250219
vertex_ai_project: "my-test-project"
vertex_ai_location: "us-west-1"
- 启动代理
litellm --config /path/to/config.yaml
- 测试一下!
curl http://0.0.0.0:4000/v1/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer <YOUR-LITELLM-KEY>" \
-d '{
"model": "claude-3-7-sonnet-20250219",
"messages": [{"role": "user", "content": "What is the capital of France?"}],
"thinking": {"type": "enabled", "budget_tokens": 1024}
}'
预期响应
ModelResponse(
id='chatcmpl-c542d76d-f675-4e87-8e5f-05855f5d0f5e',
created=1740470510,
model='claude-3-7-sonnet-20250219',
object='chat.completion',
system_fingerprint=None,
choices=[
Choices(
finish_reason='stop',
index=0,
message=Message(
content="The capital of France is Paris.",
role='assistant',
tool_calls=None,
function_call=None,
provider_specific_fields={
'citations': None,
'thinking_blocks': [
{
'type': 'thinking',
'thinking': 'The capital of France is Paris. This is a very straightforward factual question.',
'signature': 'EuYBCkQYAiJAy6...'
}
]
}
),
thinking_blocks=[
{
'type': 'thinking',
'thinking': 'The capital of France is Paris. This is a very straightforward factual question.',
'signature': 'EuYBCkQYAiJAy6AGB...'
}
],
reasoning_content='The capital of France is Paris. This is a very straightforward factual question.'
)
],
usage=Usage(
completion_tokens=68,
prompt_tokens=42,
total_tokens=110,
completion_tokens_details=None,
prompt_tokens_details=PromptTokensDetailsWrapper(
audio_tokens=None,
cached_tokens=0,
text_tokens=None,
image_tokens=None
),
cache_creation_input_tokens=0,
cache_read_input_tokens=0
)
)
Meta/Llama API
| 模型名称 | 函数调用 |
|---|---|
| meta/llama-3.2-90b-vision-instruct-maas | completion('vertex_ai/meta/llama-3.2-90b-vision-instruct-maas', messages) |
| meta/llama3-8b-instruct-maas | completion('vertex_ai/meta/llama3-8b-instruct-maas', messages) |
| meta/llama3-70b-instruct-maas | completion('vertex_ai/meta/llama3-70b-instruct-maas', messages) |
| meta/llama3-405b-instruct-maas | completion('vertex_ai/meta/llama3-405b-instruct-maas', messages) |
| meta/llama-4-scout-17b-16e-instruct-maas | completion('vertex_ai/meta/llama-4-scout-17b-16e-instruct-maas', messages) |
| meta/llama-4-scout-17-128e-instruct-maas | completion('vertex_ai/meta/llama-4-scout-128b-16e-instruct-maas', messages) |
| meta/llama-4-maverick-17b-128e-instruct-maas | completion('vertex_ai/meta/llama-4-maverick-17b-128e-instruct-maas',messages) |
| meta/llama-4-maverick-17b-16e-instruct-maas | completion('vertex_ai/meta/llama-4-maverick-17b-16e-instruct-maas',messages) |
用法
- SDK
- 代理
from litellm import completion
import os
os.environ["GOOGLE_APPLICATION_CREDENTIALS"] = ""
model = "meta/llama3-405b-instruct-maas"
vertex_ai_project = "your-vertex-project" # can also set this as os.environ["VERTEXAI_PROJECT"]
vertex_ai_location = "your-vertex-location" # can also set this as os.environ["VERTEXAI_LOCATION"]
response = completion(
model="vertex_ai/" + model,
messages=[{"role": "user", "content": "hi"}],
vertex_ai_project=vertex_ai_project,
vertex_ai_location=vertex_ai_location,
)
print("\nModel Response", response)
1. 添加到 config
model_list:
- model_name: anthropic-llama
litellm_params:
model: vertex_ai/meta/llama3-405b-instruct-maas
vertex_ai_project: "my-test-project"
vertex_ai_location: "us-east-1"
- model_name: anthropic-llama
litellm_params:
model: vertex_ai/meta/llama3-405b-instruct-maas
vertex_ai_project: "my-test-project"
vertex_ai_location: "us-west-1"
2. 启动代理
litellm --config /path/to/config.yaml
# RUNNING at http://0.0.0.0:4000
3. 测试一下!
curl --location 'http://0.0.0.0:4000/chat/completions' \
--header 'Authorization: Bearer sk-1234' \
--header 'Content-Type: application/json' \
--data '{
"model": "anthropic-llama", # 👈 the 'model_name' in config
"messages": [
{
"role": "user",
"content": "what llm are you"
}
],
}'
Mistral API
| 模型名称 | 函数调用 |
|---|---|
| mistral-large@latest | completion('vertex_ai/mistral-large@latest', messages) |
| mistral-large@2407 | completion('vertex_ai/mistral-large@2407', messages) |
| mistral-nemo@latest | completion('vertex_ai/mistral-nemo@latest', messages) |
| codestral@latest | completion('vertex_ai/codestral@latest', messages) |
| codestral@@2405 | completion('vertex_ai/codestral@2405', messages) |
用法
- SDK
- 代理
from litellm import completion
import os
os.environ["GOOGLE_APPLICATION_CREDENTIALS"] = ""
model = "mistral-large@2407"
vertex_ai_project = "your-vertex-project" # can also set this as os.environ["VERTEXAI_PROJECT"]
vertex_ai_location = "your-vertex-location" # can also set this as os.environ["VERTEXAI_LOCATION"]
response = completion(
model="vertex_ai/" + model,
messages=[{"role": "user", "content": "hi"}],
vertex_ai_project=vertex_ai_project,
vertex_ai_location=vertex_ai_location,
)
print("\nModel Response", response)
1. 添加到 config
model_list:
- model_name: vertex-mistral
litellm_params:
model: vertex_ai/mistral-large@2407
vertex_ai_project: "my-test-project"
vertex_ai_location: "us-east-1"
- model_name: vertex-mistral
litellm_params:
model: vertex_ai/mistral-large@2407
vertex_ai_project: "my-test-project"
vertex_ai_location: "us-west-1"
2. 启动代理
litellm --config /path/to/config.yaml
# RUNNING at http://0.0.0.0:4000
3. 测试一下!
curl --location 'http://0.0.0.0:4000/chat/completions' \
--header 'Authorization: Bearer sk-1234' \
--header 'Content-Type: application/json' \
--data '{
"model": "vertex-mistral", # 👈 the 'model_name' in config
"messages": [
{
"role": "user",
"content": "what llm are you"
}
],
}'
用法 - Codestral FIM
通过 OpenAI /v1/completion 端点在 VertexAI 上调用 Codestral,用于 FIM 任务。
注意:您也可以通过 /chat/completion 调用 Codestral。
- SDK
- 代理
from litellm import completion
import os
# os.environ["GOOGLE_APPLICATION_CREDENTIALS"] = ""
# OR run `!gcloud auth print-access-token` in your terminal
model = "codestral@2405"
vertex_ai_project = "your-vertex-project" # can also set this as os.environ["VERTEXAI_PROJECT"]
vertex_ai_location = "your-vertex-location" # can also set this as os.environ["VERTEXAI_LOCATION"]
response = text_completion(
model="vertex_ai/" + model,
vertex_ai_project=vertex_ai_project,
vertex_ai_location=vertex_ai_location,
prompt="def is_odd(n): \n return n % 2 == 1 \ndef test_is_odd():",
suffix="return True", # optional
temperature=0, # optional
top_p=1, # optional
max_tokens=10, # optional
min_tokens=10, # optional
seed=10, # optional
stop=["return"], # optional
)
print("\nModel Response", response)
1. 添加到 config
model_list:
- model_name: vertex-codestral
litellm_params:
model: vertex_ai/codestral@2405
vertex_ai_project: "my-test-project"
vertex_ai_location: "us-east-1"
- model_name: vertex-codestral
litellm_params:
model: vertex_ai/codestral@2405
vertex_ai_project: "my-test-project"
vertex_ai_location: "us-west-1"
2. 启动代理
litellm --config /path/to/config.yaml
# RUNNING at http://0.0.0.0:4000
3. 测试一下!
curl -X POST 'http://0.0.0.0:4000/completions' \
-H 'Authorization: Bearer sk-1234' \
-H 'Content-Type: application/json' \
-d '{
"model": "vertex-codestral", # 👈 the 'model_name' in config
"prompt": "def is_odd(n): \n return n % 2 == 1 \ndef test_is_odd():",
"suffix":"return True", # optional
"temperature":0, # optional
"top_p":1, # optional
"max_tokens":10, # optional
"min_tokens":10, # optional
"seed":10, # optional
"stop":["return"], # optional
}'
AI21 模型
| 模型名称 | 函数调用 |
|---|---|
| jamba-1.5-mini@001 | completion(model='vertex_ai/jamba-1.5-mini@001', messages) |
| jamba-1.5-large@001 | completion(model='vertex_ai/jamba-1.5-large@001', messages) |
用法
- SDK
- 代理
from litellm import completion
import os
os.environ["GOOGLE_APPLICATION_CREDENTIALS"] = ""
model = "meta/jamba-1.5-mini@001"
vertex_ai_project = "your-vertex-project" # can also set this as os.environ["VERTEXAI_PROJECT"]
vertex_ai_location = "your-vertex-location" # can also set this as os.environ["VERTEXAI_LOCATION"]
response = completion(
model="vertex_ai/" + model,
messages=[{"role": "user", "content": "hi"}],
vertex_ai_project=vertex_ai_project,
vertex_ai_location=vertex_ai_location,
)
print("\nModel Response", response)
1. 添加到 config
model_list:
- model_name: jamba-1.5-mini
litellm_params:
model: vertex_ai/jamba-1.5-mini@001
vertex_ai_project: "my-test-project"
vertex_ai_location: "us-east-1"
- model_name: jamba-1.5-large
litellm_params:
model: vertex_ai/jamba-1.5-large@001
vertex_ai_project: "my-test-project"
vertex_ai_location: "us-west-1"
2. 启动代理
litellm --config /path/to/config.yaml
# RUNNING at http://0.0.0.0:4000
3. 测试一下!
curl --location 'http://0.0.0.0:4000/chat/completions' \
--header 'Authorization: Bearer sk-1234' \
--header 'Content-Type: application/json' \
--data '{
"model": "jamba-1.5-large",
"messages": [
{
"role": "user",
"content": "what llm are you"
}
],
}'
Gemini Pro
| 模型名称 | 函数调用 |
|---|---|
| gemini-pro | completion('gemini-pro', messages), completion('vertex_ai/gemini-pro', messages) |
微调模型
您可以通过 LiteLLM 调用微调的 Vertex AI Gemini 模型
| 属性 | 详情 |
|---|---|
| 提供商路由 | vertex_ai/gemini/{MODEL_ID} |
| Vertex 文档 | Vertex AI - 微调的 Gemini 模型 |
| 支持的操作 | /chat/completions, /completions, /embeddings, /images |
要使用遵循 /gemini 请求/响应格式的模型,只需将 model 参数设置为
model="vertex_ai/gemini/<your-finetuned-model>"
- LiteLLM Python SDK
- LiteLLM 代理
import litellm
import os
## set ENV variables
os.environ["VERTEXAI_PROJECT"] = "hardy-device-38811"
os.environ["VERTEXAI_LOCATION"] = "us-central1"
response = litellm.completion(
model="vertex_ai/gemini/<your-finetuned-model>", # e.g. vertex_ai/gemini/4965075652664360960
messages=[{ "content": "Hello, how are you?","role": "user"}],
)
- 将 Vertex 凭据添加到您的环境变量
!gcloud auth application-default login
- 设置 config.yaml
- model_name: finetuned-gemini
litellm_params:
model: vertex_ai/gemini/<ENDPOINT_ID>
vertex_project: <PROJECT_ID>
vertex_location: <LOCATION>
- 测试一下!
- OpenAI Python SDK
- curl
from openai import OpenAI
client = OpenAI(
api_key="your-litellm-key",
base_url="http://0.0.0.0:4000"
)
response = client.chat.completions.create(
model="finetuned-gemini",
messages=[
{"role": "user", "content": "hi"}
]
)
print(response)
curl --location 'https://0.0.0.0:4000/v1/chat/completions' \
--header 'Content-Type: application/json' \
--header 'Authorization: <LITELLM_KEY>' \
--data '{"model": "finetuned-gemini" ,"messages":[{"role": "user", "content":[{"type": "text", "text": "hi"}]}]}'
Model Garden
支持 Vertex Model Garden 中的所有 OpenAI 兼容模型。
使用 Model Garden
几乎所有 Vertex Model Garden 模型都与 OpenAI 兼容。
- OpenAI 兼容模型
- 非 OpenAI 兼容模型
| 属性 | 详情 |
|---|---|
| 提供商路由 | vertex_ai/openai/{MODEL_ID} |
| Vertex 文档 | Vertex Model Garden - OpenAI 对话补全, Vertex Model Garden |
| 支持的操作 | /chat/completions, /embeddings |
- SDK
- 代理
from litellm import completion
import os
## set ENV variables
os.environ["VERTEXAI_PROJECT"] = "hardy-device-38811"
os.environ["VERTEXAI_LOCATION"] = "us-central1"
response = completion(
model="vertex_ai/openai/<your-endpoint-id>",
messages=[{ "content": "Hello, how are you?","role": "user"}]
)
1. 添加到 config
model_list:
- model_name: llama3-1-8b-instruct
litellm_params:
model: vertex_ai/openai/5464397967697903616
vertex_ai_project: "my-test-project"
vertex_ai_location: "us-east-1"
2. 启动代理
litellm --config /path/to/config.yaml
# RUNNING at http://0.0.0.0:4000
3. 测试一下!
curl --location 'http://0.0.0.0:4000/chat/completions' \
--header 'Authorization: Bearer sk-1234' \
--header 'Content-Type: application/json' \
--data '{
"model": "llama3-1-8b-instruct", # 👈 the 'model_name' in config
"messages": [
{
"role": "user",
"content": "what llm are you"
}
],
}'
from litellm import completion
import os
## set ENV variables
os.environ["VERTEXAI_PROJECT"] = "hardy-device-38811"
os.environ["VERTEXAI_LOCATION"] = "us-central1"
response = completion(
model="vertex_ai/<your-endpoint-id>",
messages=[{ "content": "Hello, how are you?","role": "user"}]
)
Gemini Pro Vision
| 模型名称 | 函数调用 |
|---|---|
| gemini-pro-vision | completion('gemini-pro-vision', messages), completion('vertex_ai/gemini-pro-vision', messages) |
Gemini 1.5 Pro(及 Vision)
| 模型名称 | 函数调用 |
|---|---|
| gemini-1.5-pro | completion('gemini-1.5-pro', messages), completion('vertex_ai/gemini-1.5-pro', messages) |
| gemini-1.5-flash-preview-0514 | completion('gemini-1.5-flash-preview-0514', messages), completion('vertex_ai/gemini-1.5-flash-preview-0514', messages) |
| gemini-1.5-pro-preview-0514 | completion('gemini-1.5-pro-preview-0514', messages), completion('vertex_ai/gemini-1.5-pro-preview-0514', messages) |
使用 Gemini Pro Vision
以与 OpenAI gpt-4-vision 相同的输入/输出格式调用 gemini-pro-vision
LiteLLM 支持在 url 中传递以下图像类型
- 具有 Cloud Storage URI 的图像 - gs://cloud-samples-data/generative-ai/image/boats.jpeg
- 具有直接链接的图像 - https://storage.googleapis.com/github-repo/img/gemini/intro/landmark3.jpg
- 具有 Cloud Storage URI 的视频 - https://storage.googleapis.com/github-repo/img/gemini/multimodality_usecases_overview/pixel8.mp4
- Base64 编码的本地图像
示例请求 - 图像 URL
- 具有直接链接的图像
- 本地 Base64 图像
import litellm
response = litellm.completion(
model = "vertex_ai/gemini-pro-vision",
messages=[
{
"role": "user",
"content": [
{
"type": "text",
"text": "Whats in this image?"
},
{
"type": "image_url",
"image_url": {
"url": "https://upload.wikimedia.org/wikipedia/commons/thumb/d/dd/Gfp-wisconsin-madison-the-nature-boardwalk.jpg/2560px-Gfp-wisconsin-madison-the-nature-boardwalk.jpg"
}
}
]
}
],
)
print(response)
import litellm
def encode_image(image_path):
import base64
with open(image_path, "rb") as image_file:
return base64.b64encode(image_file.read()).decode("utf-8")
image_path = "cached_logo.jpg"
# Getting the base64 string
base64_image = encode_image(image_path)
response = litellm.completion(
model="vertex_ai/gemini-pro-vision",
messages=[
{
"role": "user",
"content": [
{"type": "text", "text": "Whats in this image?"},
{
"type": "image_url",
"image_url": {
"url": "data:image/jpeg;base64," + base64_image
},
},
],
}
],
)
print(response)
用法 - 函数调用
LiteLLM 支持 Vertex AI Gemini 模型的函数调用。
from litellm import completion
import os
# set env
os.environ["GOOGLE_APPLICATION_CREDENTIALS"] = ".."
os.environ["VERTEX_AI_PROJECT"] = ".."
os.environ["VERTEX_AI_LOCATION"] = ".."
tools = [
{
"type": "function",
"function": {
"name": "get_current_weather",
"description": "Get the current weather in a given location",
"parameters": {
"type": "object",
"properties": {
"location": {
"type": "string",
"description": "The city and state, e.g. San Francisco, CA",
},
"unit": {"type": "string", "enum": ["celsius", "fahrenheit"]},
},
"required": ["location"],
},
},
}
]
messages = [{"role": "user", "content": "What's the weather like in Boston today?"}]
response = completion(
model="vertex_ai/gemini-pro-vision",
messages=messages,
tools=tools,
)
# Add any assertions, here to check response args
print(response)
assert isinstance(response.choices[0].message.tool_calls[0].function.name, str)
assert isinstance(
response.choices[0].message.tool_calls[0].function.arguments, str
)
用法 - PDF / 视频 / 音频等文件
通过 LiteLLM 传递 Vertex AI 支持的任何文件。
LiteLLM 支持在 URL 中传递以下文件类型。
从 v1.65.1+ 版本开始,VertexAI 支持使用 file 消息类型。
Files with Cloud Storage URIs - gs://cloud-samples-data/generative-ai/image/boats.jpeg
Files with direct links - https://storage.googleapis.com/github-repo/img/gemini/intro/landmark3.jpg
Videos with Cloud Storage URIs - https://storage.googleapis.com/github-repo/img/gemini/multimodality_usecases_overview/pixel8.mp4
Base64 Encoded Local Files
- SDK
- 代理
使用 gs:// 或任何 URL
from litellm import completion
response = completion(
model="vertex_ai/gemini-1.5-flash",
messages=[
{
"role": "user",
"content": [
{"type": "text", "text": "You are a very professional document summarization specialist. Please summarize the given document."},
{
"type": "file",
"file": {
"file_id": "gs://cloud-samples-data/generative-ai/pdf/2403.05530.pdf",
"format": "application/pdf" # OPTIONAL - specify mime-type
}
},
],
}
],
max_tokens=300,
)
print(response.choices[0])
使用 base64
from litellm import completion
import base64
import requests
# URL of the file
url = "https://storage.googleapis.com/cloud-samples-data/generative-ai/pdf/2403.05530.pdf"
# Download the file
response = requests.get(url)
file_data = response.content
encoded_file = base64.b64encode(file_data).decode("utf-8")
response = completion(
model="vertex_ai/gemini-1.5-flash",
messages=[
{
"role": "user",
"content": [
{"type": "text", "text": "You are a very professional document summarization specialist. Please summarize the given document."},
{
"type": "file",
"file": {
"file_data": f"data:application/pdf;base64,{encoded_file}", # 👈 PDF
}
},
{
"type": "audio_input",
"audio_input {
"audio_input": f"data:audio/mp3;base64,{encoded_file}", # 👈 AUDIO File ('file' message works as too)
}
},
],
}
],
max_tokens=300,
)
print(response.choices[0])
- 将模型添加到 config
- model_name: gemini-1.5-flash
litellm_params:
model: vertex_ai/gemini-1.5-flash
vertex_credentials: "/path/to/service_account.json"
- 启动代理
litellm --config /path/to/config.yaml
- 测试一下!
使用 gs://
curl http://0.0.0.0:4000/v1/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer <YOUR-LITELLM-KEY>" \
-d '{
"model": "gemini-1.5-flash",
"messages": [
{
"role": "user",
"content": [
{
"type": "text",
"text": "You are a very professional document summarization specialist. Please summarize the given document"
},
{
"type": "file",
"file": {
"file_id": "gs://cloud-samples-data/generative-ai/pdf/2403.05530.pdf",
"format": "application/pdf" # OPTIONAL
}
}
}
]
}
],
"max_tokens": 300
}'
curl http://0.0.0.0:4000/v1/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer <YOUR-LITELLM-KEY>" \
-d '{
"model": "gemini-1.5-flash",
"messages": [
{
"role": "user",
"content": [
{
"type": "text",
"text": "You are a very professional document summarization specialist. Please summarize the given document"
},
{
"type": "file",
"file": {
"file_data": f"data:application/pdf;base64,{encoded_file}", # 👈 PDF
},
},
{
"type": "audio_input",
"audio_input {
"audio_input": f"data:audio/mp3;base64,{encoded_file}", # 👈 AUDIO File ('file' message works as too)
}
},
]
}
],
"max_tokens": 300
}'
聊天模型
| 模型名称 | 函数调用 |
|---|---|
| chat-bison-32k | completion('chat-bison-32k', messages) |
| chat-bison | completion('chat-bison', messages) |
| chat-bison@001 | completion('chat-bison@001', messages) |
代码聊天模型
| 模型名称 | 函数调用 |
|---|---|
| codechat-bison | completion('codechat-bison', messages) |
| codechat-bison-32k | completion('codechat-bison-32k', messages) |
| codechat-bison@001 | completion('codechat-bison@001', messages) |
文本模型
| 模型名称 | 函数调用 |
|---|---|
| text-bison | completion('text-bison', messages) |
| text-bison@001 | completion('text-bison@001', messages) |
代码文本模型
| 模型名称 | 函数调用 |
|---|---|
| code-bison | completion('code-bison', messages) |
| code-bison@001 | completion('code-bison@001', messages) |
| code-gecko@001 | completion('code-gecko@001', messages) |
| code-gecko@latest | completion('code-gecko@latest', messages) |
Embedding 模型
用法 - Embedding
- SDK
- LiteLLM 代理
import litellm
from litellm import embedding
litellm.vertex_project = "hardy-device-38811" # Your Project ID
litellm.vertex_location = "us-central1" # proj location
response = embedding(
model="vertex_ai/textembedding-gecko",
input=["good morning from litellm"],
)
print(response)
- 将模型添加到 config.yaml
model_list:
- model_name: snowflake-arctic-embed-m-long-1731622468876
litellm_params:
model: vertex_ai/<your-model-id>
vertex_project: "adroit-crow-413218"
vertex_location: "us-central1"
vertex_credentials: adroit-crow-413218-a956eef1a2a8.json
litellm_settings:
drop_params: True
- 启动代理
$ litellm --config /path/to/config.yaml
- 使用 OpenAI Python SDK、Langchain Python SDK 发送请求
import openai
client = openai.OpenAI(api_key="sk-1234", base_url="http://0.0.0.0:4000")
response = client.embeddings.create(
model="snowflake-arctic-embed-m-long-1731622468876",
input = ["good morning from litellm", "this is another item"],
)
print(response)
支持的 Embedding 模型
支持此处列出的所有模型
| 模型名称 | 函数调用 |
|---|---|
| text-embedding-004 | embedding(model="vertex_ai/text-embedding-004", input) |
| text-multilingual-embedding-002 | embedding(model="vertex_ai/text-multilingual-embedding-002", input) |
| textembedding-gecko | embedding(model="vertex_ai/textembedding-gecko", input) |
| textembedding-gecko-multilingual | embedding(model="vertex_ai/textembedding-gecko-multilingual", input) |
| textembedding-gecko-multilingual@001 | embedding(model="vertex_ai/textembedding-gecko-multilingual@001", input) |
| textembedding-gecko@001 | embedding(model="vertex_ai/textembedding-gecko@001", input) |
| textembedding-gecko@003 | embedding(model="vertex_ai/textembedding-gecko@003", input) |
| text-embedding-preview-0409 | embedding(model="vertex_ai/text-embedding-preview-0409", input) |
| text-multilingual-embedding-preview-0409 | embedding(model="vertex_ai/text-multilingual-embedding-preview-0409", input) |
| 微调或自定义 Embedding 模型 | embedding(model="vertex_ai/<your-model-id>", input) |
支持的 OpenAI (统一) 参数
| 参数 | 类型 | Vertex 等效项 |
|---|---|---|
input | string 或 List[string] | instances |
dimensions | int | output_dimensionality |
input_type | Literal["RETRIEVAL_QUERY","RETRIEVAL_DOCUMENT", "SEMANTIC_SIMILARITY", "CLASSIFICATION", "CLUSTERING", "QUESTION_ANSWERING", "FACT_VERIFICATION"] | task_type |
使用 OpenAI (统一) 参数的用法
- SDK
- LiteLLM 代理
response = litellm.embedding(
model="vertex_ai/text-embedding-004",
input=["good morning from litellm", "gm"]
input_type = "RETRIEVAL_DOCUMENT",
dimensions=1,
)
import openai
client = openai.OpenAI(api_key="sk-1234", base_url="http://0.0.0.0:4000")
response = client.embeddings.create(
model="text-embedding-004",
input = ["good morning from litellm", "gm"],
dimensions=1,
extra_body = {
"input_type": "RETRIEVAL_QUERY",
}
)
print(response)
支持的 Vertex 特有参数
| 参数 | 类型 |
|---|---|
auto_truncate | bool |
task_type | Literal["RETRIEVAL_QUERY","RETRIEVAL_DOCUMENT", "SEMANTIC_SIMILARITY", "CLASSIFICATION", "CLUSTERING", "QUESTION_ANSWERING", "FACT_VERIFICATION"] |
title | str |
使用 Vertex 特有参数(使用 task_type 和 title)
您可以将任何 Vertex 特有参数传递给 embedding 模型。只需像这样将它们传递给 embedding 函数
包含所有 embedding 参数的相关 Vertex AI 文档
- SDK
- LiteLLM 代理
response = litellm.embedding(
model="vertex_ai/text-embedding-004",
input=["good morning from litellm", "gm"]
task_type = "RETRIEVAL_DOCUMENT",
title = "test",
dimensions=1,
auto_truncate=True,
)
import openai
client = openai.OpenAI(api_key="sk-1234", base_url="http://0.0.0.0:4000")
response = client.embeddings.create(
model="text-embedding-004",
input = ["good morning from litellm", "gm"],
dimensions=1,
extra_body = {
"task_type": "RETRIEVAL_QUERY",
"auto_truncate": True,
"title": "test",
}
)
print(response)
多模态 Embedding
已知限制
- 每个请求仅支持 1 个图像 / 视频
- 仅支持 GCS 或 base64 编码的图像 / 视频
用法
- SDK
- LiteLLM 代理 (统一端点)
- LiteLLM 代理 (Vertex SDK)
使用 GCS 图像
response = await litellm.aembedding(
model="vertex_ai/multimodalembedding@001",
input="gs://cloud-samples-data/vertex-ai/llm/prompts/landmark1.png" # will be sent as a gcs image
)
使用 Base64 编码的图像
response = await litellm.aembedding(
model="vertex_ai/multimodalembedding@001",
input="data:image/jpeg;base64,..." # will be sent as a base64 encoded image
)
- 将模型添加到 config.yaml
model_list:
- model_name: multimodalembedding@001
litellm_params:
model: vertex_ai/multimodalembedding@001
vertex_project: "adroit-crow-413218"
vertex_location: "us-central1"
vertex_credentials: adroit-crow-413218-a956eef1a2a8.json
litellm_settings:
drop_params: True
- 启动代理
$ litellm --config /path/to/config.yaml
- 使用 OpenAI Python SDK、Langchain Python SDK 发送请求
- OpenAI SDK
- Langchain
包含 GCS 图像 / 视频 URI 的请求
import openai
client = openai.OpenAI(api_key="sk-1234", base_url="http://0.0.0.0:4000")
# # request sent to model set on litellm proxy, `litellm --model`
response = client.embeddings.create(
model="multimodalembedding@001",
input = "gs://cloud-samples-data/vertex-ai/llm/prompts/landmark1.png",
)
print(response)
包含 Base64 编码图像的请求
import openai
client = openai.OpenAI(api_key="sk-1234", base_url="http://0.0.0.0:4000")
# # request sent to model set on litellm proxy, `litellm --model`
response = client.embeddings.create(
model="multimodalembedding@001",
input = "data:image/jpeg;base64,...",
)
print(response)
包含 GCS 图像 / 视频 URI 的请求
from langchain_openai import OpenAIEmbeddings
embeddings_models = "multimodalembedding@001"
embeddings = OpenAIEmbeddings(
model="multimodalembedding@001",
base_url="http://0.0.0.0:4000",
api_key="sk-1234", # type: ignore
)
query_result = embeddings.embed_query(
"gs://cloud-samples-data/vertex-ai/llm/prompts/landmark1.png"
)
print(query_result)
包含 Base64 编码图像的请求
from langchain_openai import OpenAIEmbeddings
embeddings_models = "multimodalembedding@001"
embeddings = OpenAIEmbeddings(
model="multimodalembedding@001",
base_url="http://0.0.0.0:4000",
api_key="sk-1234", # type: ignore
)
query_result = embeddings.embed_query(
"data:image/jpeg;base64,..."
)
print(query_result)
- 将模型添加到 config.yaml
default_vertex_config:
vertex_project: "adroit-crow-413218"
vertex_location: "us-central1"
vertex_credentials: adroit-crow-413218-a956eef1a2a8.json
- 启动代理
$ litellm --config /path/to/config.yaml
- 使用 OpenAI Python SDK 发送请求
import vertexai
from vertexai.vision_models import Image, MultiModalEmbeddingModel, Video
from vertexai.vision_models import VideoSegmentConfig
from google.auth.credentials import Credentials
LITELLM_PROXY_API_KEY = "sk-1234"
LITELLM_PROXY_BASE = "http://0.0.0.0:4000/vertex-ai"
import datetime
class CredentialsWrapper(Credentials):
def __init__(self, token=None):
super().__init__()
self.token = token
self.expiry = None # or set to a future date if needed
def refresh(self, request):
pass
def apply(self, headers, token=None):
headers['Authorization'] = f'Bearer {self.token}'
@property
def expired(self):
return False # Always consider the token as non-expired
@property
def valid(self):
return True # Always consider the credentials as valid
credentials = CredentialsWrapper(token=LITELLM_PROXY_API_KEY)
vertexai.init(
project="adroit-crow-413218",
location="us-central1",
api_endpoint=LITELLM_PROXY_BASE,
credentials = credentials,
api_transport="rest",
)
model = MultiModalEmbeddingModel.from_pretrained("multimodalembedding")
image = Image.load_from_file(
"gs://cloud-samples-data/vertex-ai/llm/prompts/landmark1.png"
)
embeddings = model.get_embeddings(
image=image,
contextual_text="Colosseum",
dimension=1408,
)
print(f"Image Embedding: {embeddings.image_embedding}")
print(f"Text Embedding: {embeddings.text_embedding}")
文本 + 图像 + 视频 Embedding
- SDK
- LiteLLM 代理 (统一端点)
文本 + 图像
response = await litellm.aembedding(
model="vertex_ai/multimodalembedding@001",
input=["hey", "gs://cloud-samples-data/vertex-ai/llm/prompts/landmark1.png"] # will be sent as a gcs image
)
文本 + 视频
response = await litellm.aembedding(
model="vertex_ai/multimodalembedding@001",
input=["hey", "gs://my-bucket/embeddings/supermarket-video.mp4"] # will be sent as a gcs image
)
图像 + 视频
response = await litellm.aembedding(
model="vertex_ai/multimodalembedding@001",
input=["gs://cloud-samples-data/vertex-ai/llm/prompts/landmark1.png", "gs://my-bucket/embeddings/supermarket-video.mp4"] # will be sent as a gcs image
)
- 将模型添加到 config.yaml
model_list:
- model_name: multimodalembedding@001
litellm_params:
model: vertex_ai/multimodalembedding@001
vertex_project: "adroit-crow-413218"
vertex_location: "us-central1"
vertex_credentials: adroit-crow-413218-a956eef1a2a8.json
litellm_settings:
drop_params: True
- 启动代理
$ litellm --config /path/to/config.yaml
- 使用 OpenAI Python SDK、Langchain Python SDK 发送请求
文本 + 图像
import openai
client = openai.OpenAI(api_key="sk-1234", base_url="http://0.0.0.0:4000")
# # request sent to model set on litellm proxy, `litellm --model`
response = client.embeddings.create(
model="multimodalembedding@001",
input = ["hey", "gs://cloud-samples-data/vertex-ai/llm/prompts/landmark1.png"],
)
print(response)
文本 + 视频
import openai
client = openai.OpenAI(api_key="sk-1234", base_url="http://0.0.0.0:4000")
# # request sent to model set on litellm proxy, `litellm --model`
response = client.embeddings.create(
model="multimodalembedding@001",
input = ["hey", "gs://my-bucket/embeddings/supermarket-video.mp4"],
)
print(response)
图像 + 视频
import openai
client = openai.OpenAI(api_key="sk-1234", base_url="http://0.0.0.0:4000")
# # request sent to model set on litellm proxy, `litellm --model`
response = client.embeddings.create(
model="multimodalembedding@001",
input = ["gs://cloud-samples-data/vertex-ai/llm/prompts/landmark1.png", "gs://my-bucket/embeddings/supermarket-video.mp4"],
)
print(response)
图像生成模型
用法
response = await litellm.aimage_generation(
prompt="An olympic size swimming pool",
model="vertex_ai/imagegeneration@006",
vertex_ai_project="adroit-crow-413218",
vertex_ai_location="us-central1",
)
生成多个图像
使用 n 参数传递要生成的图像数量
response = await litellm.aimage_generation(
prompt="An olympic size swimming pool",
model="vertex_ai/imagegeneration@006",
vertex_ai_project="adroit-crow-413218",
vertex_ai_location="us-central1",
n=1,
)
支持的图像生成模型
| 模型名称 | 用法 |
|---|---|
imagen-3.0-generate-001 | litellm.image_generation('vertex_ai/imagen-3.0-generate-001', prompt) |
imagen-3.0-fast-generate-001 | litellm.image_generation('vertex_ai/imagen-3.0-fast-generate-001', prompt) |
imagegeneration@006 | litellm.image_generation('vertex_ai/imagegeneration@006', prompt) |
imagegeneration@005 | litellm.image_generation('vertex_ai/imagegeneration@005', prompt) |
imagegeneration@002 | litellm.image_generation('vertex_ai/imagegeneration@002', prompt) |
文本转语音 API
LiteLLM 支持以 OpenAI 文本转语音 API 格式调用 Vertex AI 文本转语音 API
用法 - 基本
- SDK
- LiteLLM 代理 (统一端点)
Vertex AI 不支持传递 model 参数 - 因此传递 model=vertex_ai/ 是唯一必需的参数
同步用法
speech_file_path = Path(__file__).parent / "speech_vertex.mp3"
response = litellm.speech(
model="vertex_ai/",
input="hello what llm guardrail do you have",
)
response.stream_to_file(speech_file_path)
异步用法
speech_file_path = Path(__file__).parent / "speech_vertex.mp3"
response = litellm.aspeech(
model="vertex_ai/",
input="hello what llm guardrail do you have",
)
response.stream_to_file(speech_file_path)
- 将模型添加到 config.yaml
model_list:
- model_name: vertex-tts
litellm_params:
model: vertex_ai/ # Vertex AI does not support passing a `model` param - so passing `model=vertex_ai/` is the only required param
vertex_project: "adroit-crow-413218"
vertex_location: "us-central1"
vertex_credentials: adroit-crow-413218-a956eef1a2a8.json
litellm_settings:
drop_params: True
- 启动代理
$ litellm --config /path/to/config.yaml
- 使用 OpenAI Python SDK 发送请求
import openai
client = openai.OpenAI(api_key="sk-1234", base_url="http://0.0.0.0:4000")
# see supported values for "voice" on vertex here:
# https://console.cloud.google.com/vertex-ai/generative/speech/text-to-speech
response = client.audio.speech.create(
model = "vertex-tts",
input="the quick brown fox jumped over the lazy dogs",
voice={'languageCode': 'en-US', 'name': 'en-US-Studio-O'}
)
print("response from proxy", response)
用法 - 将 ssml 作为输入
将您的 ssml 作为输入传递给 input 参数,如果它包含 <speak>,它将被自动检测并作为 ssml 传递给 Vertex AI API
如果您需要强制将 input 作为 ssml 传递,请设置 use_ssml=True
- SDK
- LiteLLM 代理 (统一端点)
Vertex AI 不支持传递 model 参数 - 因此传递 model=vertex_ai/ 是唯一必需的参数
speech_file_path = Path(__file__).parent / "speech_vertex.mp3"
ssml = """
<speak>
<p>Hello, world!</p>
<p>This is a test of the <break strength="medium" /> text-to-speech API.</p>
</speak>
"""
response = litellm.speech(
input=ssml,
model="vertex_ai/test",
voice={
"languageCode": "en-UK",
"name": "en-UK-Studio-O",
},
audioConfig={
"audioEncoding": "LINEAR22",
"speakingRate": "10",
},
)
response.stream_to_file(speech_file_path)
import openai
client = openai.OpenAI(api_key="sk-1234", base_url="http://0.0.0.0:4000")
ssml = """
<speak>
<p>Hello, world!</p>
<p>This is a test of the <break strength="medium" /> text-to-speech API.</p>
</speak>
"""
# see supported values for "voice" on vertex here:
# https://console.cloud.google.com/vertex-ai/generative/speech/text-to-speech
response = client.audio.speech.create(
model = "vertex-tts",
input=ssml,
voice={'languageCode': 'en-US', 'name': 'en-US-Studio-O'},
)
print("response from proxy", response)
强制使用 SSML
您可以通过将 use_ssml 参数设置为 True 来强制使用 SSML。当您想确保输入被视为 SSML,即使它不包含 <speak> 标签时,这非常有用。
以下是强制使用 SSML 的示例
- SDK
- LiteLLM 代理 (统一端点)
Vertex AI 不支持传递 model 参数 - 因此传递 model=vertex_ai/ 是唯一必需的参数
speech_file_path = Path(__file__).parent / "speech_vertex.mp3"
ssml = """
<speak>
<p>Hello, world!</p>
<p>This is a test of the <break strength="medium" /> text-to-speech API.</p>
</speak>
"""
response = litellm.speech(
input=ssml,
use_ssml=True,
model="vertex_ai/test",
voice={
"languageCode": "en-UK",
"name": "en-UK-Studio-O",
},
audioConfig={
"audioEncoding": "LINEAR22",
"speakingRate": "10",
},
)
response.stream_to_file(speech_file_path)
import openai
client = openai.OpenAI(api_key="sk-1234", base_url="http://0.0.0.0:4000")
ssml = """
<speak>
<p>Hello, world!</p>
<p>This is a test of the <break strength="medium" /> text-to-speech API.</p>
</speak>
"""
# see supported values for "voice" on vertex here:
# https://console.cloud.google.com/vertex-ai/generative/speech/text-to-speech
response = client.audio.speech.create(
model = "vertex-tts",
input=ssml, # pass as None since OpenAI SDK requires this param
voice={'languageCode': 'en-US', 'name': 'en-US-Studio-O'},
extra_body={"use_ssml": True},
)
print("response from proxy", response)
批量 API
只需将以下 Vertex 环境变量添加到您的环境中。
# GCS Bucket settings, used to store batch prediction files in
export GCS_BUCKET_NAME = "litellm-testing-bucket" # the bucket you want to store batch prediction files in
export GCS_PATH_SERVICE_ACCOUNT="/path/to/service_account.json" # path to your service account json file
# Vertex /batch endpoint settings, used for LLM API requests
export GOOGLE_APPLICATION_CREDENTIALS="/path/to/service_account.json" # path to your service account json file
export VERTEXAI_LOCATION="us-central1" # can be any vertex location
export VERTEXAI_PROJECT="my-test-project"
用法
1. 为 Vertex 创建一个批量请求文件
LiteLLM 要求文件遵循 OpenAI 批量文件格式
文件中的每个 body 都应该是一个 OpenAI API 请求
在当前工作目录中创建一个名为 vertex_batch_completions.jsonl 的文件,其中的 model 应为 Vertex AI 模型名称
{"custom_id": "request-1", "method": "POST", "url": "/v1/chat/completions", "body": {"model": "gemini-1.5-flash-001", "messages": [{"role": "system", "content": "You are a helpful assistant."},{"role": "user", "content": "Hello world!"}],"max_tokens": 10}}
{"custom_id": "request-2", "method": "POST", "url": "/v1/chat/completions", "body": {"model": "gemini-1.5-flash-001", "messages": [{"role": "system", "content": "You are an unhelpful assistant."},{"role": "user", "content": "Hello world!"}],"max_tokens": 10}}
2. 上传批量请求文件
对于 vertex_ai,liteLLM 会将文件上传到提供的 GCS_BUCKET_NAME
import os
oai_client = OpenAI(
api_key="sk-1234", # litellm proxy API key
base_url="https://:4000" # litellm proxy base url
)
file_name = "vertex_batch_completions.jsonl" #
_current_dir = os.path.dirname(os.path.abspath(__file__))
file_path = os.path.join(_current_dir, file_name)
file_obj = oai_client.files.create(
file=open(file_path, "rb"),
purpose="batch",
extra_body={"custom_llm_provider": "vertex_ai"}, # tell litellm to use vertex_ai for this file upload
)
预期响应
{
"id": "gs://litellm-testing-bucket/litellm-vertex-files/publishers/google/models/gemini-1.5-flash-001/d3f198cd-c0d1-436d-9b1e-28e3f282997a",
"bytes": 416,
"created_at": 1733392026,
"filename": "litellm-vertex-files/publishers/google/models/gemini-1.5-flash-001/d3f198cd-c0d1-436d-9b1e-28e3f282997a",
"object": "file",
"purpose": "batch",
"status": "uploaded",
"status_details": null
}
3. 创建批量
batch_input_file_id = file_obj.id # use `file_obj` from step 2
create_batch_response = oai_client.batches.create(
completion_window="24h",
endpoint="/v1/chat/completions",
input_file_id=batch_input_file_id, # example input_file_id = "gs://litellm-testing-bucket/litellm-vertex-files/publishers/google/models/gemini-1.5-flash-001/c2b1b785-252b-448c-b180-033c4c63b3ce"
extra_body={"custom_llm_provider": "vertex_ai"}, # tell litellm to use `vertex_ai` for this batch request
)
预期响应
{
"id": "3814889423749775360",
"completion_window": "24hrs",
"created_at": 1733392026,
"endpoint": "",
"input_file_id": "gs://litellm-testing-bucket/litellm-vertex-files/publishers/google/models/gemini-1.5-flash-001/d3f198cd-c0d1-436d-9b1e-28e3f282997a",
"object": "batch",
"status": "validating",
"cancelled_at": null,
"cancelling_at": null,
"completed_at": null,
"error_file_id": null,
"errors": null,
"expired_at": null,
"expires_at": null,
"failed_at": null,
"finalizing_at": null,
"in_progress_at": null,
"metadata": null,
"output_file_id": "gs://litellm-testing-bucket/litellm-vertex-files/publishers/google/models/gemini-1.5-flash-001",
"request_counts": null
}
4. 检索批量
retrieved_batch = oai_client.batches.retrieve(
batch_id=create_batch_response.id,
extra_body={"custom_llm_provider": "vertex_ai"}, # tell litellm to use `vertex_ai` for this batch request
)
预期响应
{
"id": "3814889423749775360",
"completion_window": "24hrs",
"created_at": 1736500100,
"endpoint": "",
"input_file_id": "gs://example-bucket-1-litellm/litellm-vertex-files/publishers/google/models/gemini-1.5-flash-001/7b2e47f5-3dd4-436d-920f-f9155bbdc952",
"object": "batch",
"status": "completed",
"cancelled_at": null,
"cancelling_at": null,
"completed_at": null,
"error_file_id": null,
"errors": null,
"expired_at": null,
"expires_at": null,
"failed_at": null,
"finalizing_at": null,
"in_progress_at": null,
"metadata": null,
"output_file_id": "gs://example-bucket-1-litellm/litellm-vertex-files/publishers/google/models/gemini-1.5-flash-001",
"request_counts": null
}
微调 API
| 属性 | 详情 |
|---|---|
| 描述 | 使用 OpenAI Python SDK 在 Vertex AI 中创建微调任务(/tuningJobs) |
| Vertex 微调文档 | Vertex 微调 |
用法
1. 将 finetune_settings 添加到 config.yaml
model_list:
- model_name: gpt-4
litellm_params:
model: openai/fake
api_key: fake-key
api_base: https://exampleopenaiendpoint-production.up.railway.app/
# 👇 Key change: For /fine_tuning/jobs endpoints
finetune_settings:
- custom_llm_provider: "vertex_ai"
vertex_project: "adroit-crow-413218"
vertex_location: "us-central1"
vertex_credentials: "/Users/ishaanjaffer/Downloads/adroit-crow-413218-a956eef1a2a8.json"
2. 创建微调任务
- OpenAI Python SDK
- curl
ft_job = await client.fine_tuning.jobs.create(
model="gemini-1.0-pro-002", # Vertex model you want to fine-tune
training_file="gs://cloud-samples-data/ai-platform/generative_ai/sft_train_data.jsonl", # file_id from create file response
extra_body={"custom_llm_provider": "vertex_ai"}, # tell litellm proxy which provider to use
)
curl https://:4000/v1/fine_tuning/jobs \
-H "Content-Type: application/json" \
-H "Authorization: Bearer sk-1234" \
-d '{
"custom_llm_provider": "vertex_ai",
"model": "gemini-1.0-pro-002",
"training_file": "gs://cloud-samples-data/ai-platform/generative_ai/sft_train_data.jsonl"
}'
高级用例 - 将 adapter_size 传递给 Vertex AI API
设置超参数,例如 n_epochs、learning_rate_multiplier 和 adapter_size。请参阅 Vertex 高级超参数
- OpenAI Python SDK
- curl
ft_job = client.fine_tuning.jobs.create(
model="gemini-1.0-pro-002", # Vertex model you want to fine-tune
training_file="gs://cloud-samples-data/ai-platform/generative_ai/sft_train_data.jsonl", # file_id from create file response
hyperparameters={
"n_epochs": 3, # epoch_count on Vertex
"learning_rate_multiplier": 0.1, # learning_rate_multiplier on Vertex
"adapter_size": "ADAPTER_SIZE_ONE" # type: ignore, vertex specific hyperparameter
},
extra_body={
"custom_llm_provider": "vertex_ai",
},
)
curl https://:4000/v1/fine_tuning/jobs \
-H "Content-Type: application/json" \
-H "Authorization: Bearer sk-1234" \
-d '{
"custom_llm_provider": "vertex_ai",
"model": "gemini-1.0-pro-002",
"training_file": "gs://cloud-samples-data/ai-platform/generative_ai/sft_train_data.jsonl",
"hyperparameters": {
"n_epochs": 3,
"learning_rate_multiplier": 0.1,
"adapter_size": "ADAPTER_SIZE_ONE"
}
}'
补充
使用 GOOGLE_APPLICATION_CREDENTIALS
以下是将您的服务帐号凭据存储为 GOOGLE_APPLICATION_CREDENTIALS 环境变量的代码
import os
import tempfile
def load_vertex_ai_credentials():
# Define the path to the vertex_key.json file
print("loading vertex ai credentials")
filepath = os.path.dirname(os.path.abspath(__file__))
vertex_key_path = filepath + "/vertex_key.json"
# Read the existing content of the file or create an empty dictionary
try:
with open(vertex_key_path, "r") as file:
# Read the file content
print("Read vertexai file path")
content = file.read()
# If the file is empty or not valid JSON, create an empty dictionary
if not content or not content.strip():
service_account_key_data = {}
else:
# Attempt to load the existing JSON content
file.seek(0)
service_account_key_data = json.load(file)
except FileNotFoundError:
# If the file doesn't exist, create an empty dictionary
service_account_key_data = {}
# Create a temporary file
with tempfile.NamedTemporaryFile(mode="w+", delete=False) as temp_file:
# Write the updated content to the temporary file
json.dump(service_account_key_data, temp_file, indent=2)
# Export the temporary file as GOOGLE_APPLICATION_CREDENTIALS
os.environ["GOOGLE_APPLICATION_CREDENTIALS"] = os.path.abspath(temp_file.name)
使用 GCP 服务帐号
尝试在 Google Cloud Run 上部署 LiteLLM?教程在此
- 找出绑定到 Google Cloud Run 服务的服务帐号
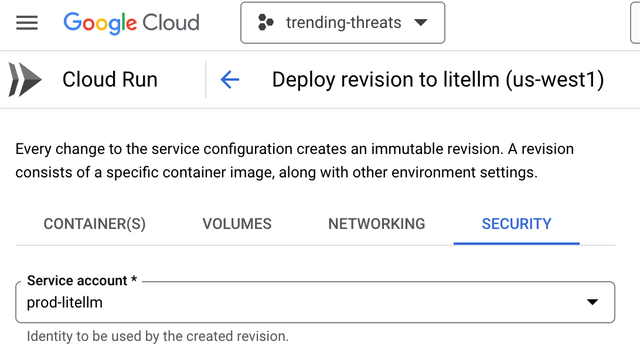
获取对应服务帐号的完整电子邮件地址
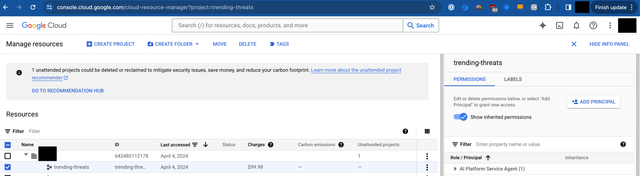
接下来,转到 IAM 与 Admin > 管理资源,选择包含您的 Google Cloud Run 服务的顶级项目
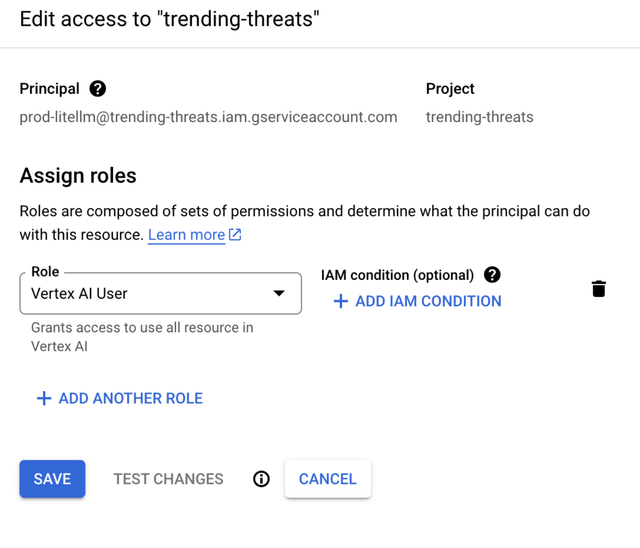
点击 Add Principal
- 指定服务帐号作为主体,Vertex AI 用户作为角色
完成后,当您在 Google Cloud Run 服务中部署新的容器时,LiteLLM 将自动访问所有 Vertex AI 端点。
特别感谢 @Darien Kindlund 提供此教程